





Break that big ball of mud!
This article was originally published on the NDC 2016 Blog.

Have you ever had to deal with a function that had hundreds and hundreds of lines? Code that had duplication all over the place? Chances are you were dealing with legacy code that was written years ago. If you’re a Star Wars fan like I am, it’s like dealing with the Force. As Yoda would say, “Fear is the path to the dark side. Fear leads to anger. Anger leads to hate. Hate leads to suffering.”
In my 15+ years of coding, every single time I’ve dealt with legacy code, fear, anger, hate, and suffering were pretty common.
Fear: I fear that monster two-thousand-line function because I know what lies beneath in that monster function. Absolutely nothing good!
Anger: I get angry when I see code repeated all over the place. On one occasion, I came across 50 modules that had the same ten lines of code. That code was trying to look up a registry key to find some detail and then writing back to HKLM. Remember the time when Vista OS introduced new OS security features? Applications with standard user access could not write to the HKLM registry keys. To be Vista compliant, the same ten lines of code needed a change in not one but 50 modules!
Hate: Of course, the next natural emotion is hate, leading to a lot of WTF moments looking at the code. What in the world was that developer thinking!? When you start duplicating the code for the second time why didn’t the alarm bells go off, let alone the 50th time!
Suffering: All this naturally leads to suffering, just like the wise Yoda predicted. Because, at the end of the day, why the existing codebase has its quirks doesn’t matter. It just does, and I’m the one that has to deal with it.
Unfortunately, I am not the only one in our industry who goes through these same emotions. Many of us experience them on a daily basis. You’re probably in that same boat.
You think you could probably do better. The codebase is so bad that it needs a rewrite. You look at the smart developer team around you and think, “We’ve got this.” Technology is much better than it was all those years ago when that legacy project began. You now have newer frameworks in your toolbox. What could possibly go wrong?
🔗The “All New” Death Star?
The problem is that it requires time to wrap your head around the many nuances and nooks and crannies in that legacy code. While you might be convinced that these are the exact reasons that warrant the rewrite, chances are you’ll miss a few details that might be important to your business. These oversights might end up as costly mistakes later.
You may not be able to get away from your responsibility of fixing existing bugs. You might also have to add new and important features to the existing codebase to satisfy customer needs. What if you still have to support the existing system? As you’re rewriting the system, how are you going to deal with these new feature requests for customers?
If you’ve scanned the existing code and compiled a list of features, you probably know it’s going to take you a long time to get the rewrite done. Months? Years? A lot can happen in that time frame. What was relevant when you first started may no longer be relevant when you finish.
How do you plan to sell the rewrite to business stakeholders? A rewrite based purely on technical concerns (like upgrading .NET Framework versions) won’t sound like a convincing reason to them. If the multi-year rewrite plan does get approved by the business, what’s to say you won’t be making the same mistakes as your predecessors but with the technology of today? What if you accidentally end up building a new Death Star?
🔗A New Hope
As part of supporting existing customers, it’s likely you add new features to your system. Working on a greenfield project is every developer’s dream. It’s a place filled with unit tests, automated integration tests, and code written using the “most latest” framework in town. Adding new features to existing legacy code and supporting existing customers, on the other hand, is tricky. To do it right, without breaking existing features, you’ll have to try and find your inner Jedi.
“Use the Force, Luke.”
“Thank you, Obi-Wan. If only it were that simple!”
The young Luke Skywalker’s job was simple. He fired those missiles and made the Death Star explode. While, you, on the other hand, now have to navigate a minefield. One line of code in the wrong place can break existing functionality. And it can upset QA, product owners, and other developers, as it might lead to slipping deadlines. Even worse is if this bug isn’t caught in the development, QA, and staging environments and only showed its nastiness in production.
While this paints a pretty dark picture, every problem has a solution.
🔗Event-Driven Architecture to the Rescue
Event-driven architecture is a software design style that uses messaging techniques to convey events to other services. It promotes asynchrony. Events are nothing but simple data transfer objects (DTO) to convey something significant that happened within your business system. They can signify a change, such as a threshold change, to indicate that something just completed, that there was a failure, etc. These events can then be used to trigger other downstream business processes.
Events typically contain the relevant identifier for the related entity, the date and time of occurrence, and other important data about the event itself. For example, the CustomerBecamePreferred event would contain relevant details, such as the CustomerId, CustomerPreferredFrom, CustomerPreferredUntil — i.e., the date and times that are relevant to this event and other important information.
When the condition in the code is met, an event is published. The interested parties of this event then take the appropriate action upon receiving it. These interested parties could be another service, which might publish another event and so on. In this model, the software system follows the natural business process.
The beauty of this model is that the publisher of the event just publishes the event. It has no knowledge of what the subscriber intends to do with it. Event-driven architecture leads to loosely coupled systems.
🔗Back to the legacy conundrum. How can event-driven architecture help?
You can now use messaging patterns like Publish-Subscribe to evolve your system. The book Enterprise Integration Patterns is a fantastic read that covers over a hundred messaging patterns you can use to solve everyday problems using asynchrony.
🔗Step 1: Add Visibility to Your Monolith
Instrumenting your monolith with events can help for a variety of reasons. First and foremost, it adds visibility inside your monolith.
You’ll first need to analyze your monolith code to find the lines that complete important actions. Now you can publish those actions as events. Repeat this process until you’ve captured all the important actions as events your monolith is performing. Adding the code to publish an event inside your monolith is less intrusive than attempting to write a brand new feature inside it. And doing this is simple, especially if you’re using an available library like NServiceBus or MassTransit.
This strategy came in handy once when my team had to discover why a process was taking so long. After we had instrumented the legacy code with events, we had a subscriber module that received all these events. Using these events, we knew how long each of these critical business processes took to complete. We were able to identify the part that took too long. It turned out that an RPC call to a legacy service, whose response value was stored in the 72nd column in the database table, wasn’t even necessary. After we had removed the offending line of code, the process was 30 times faster. Would we have found this without instrumenting? Eventually, after a few gray hairs and a whole lot of caffeine, yes. However, instrumenting with events provided visibility into a process that was opaque from the dawn of its creation, which turned out to be quite valuable in gathering other insights.
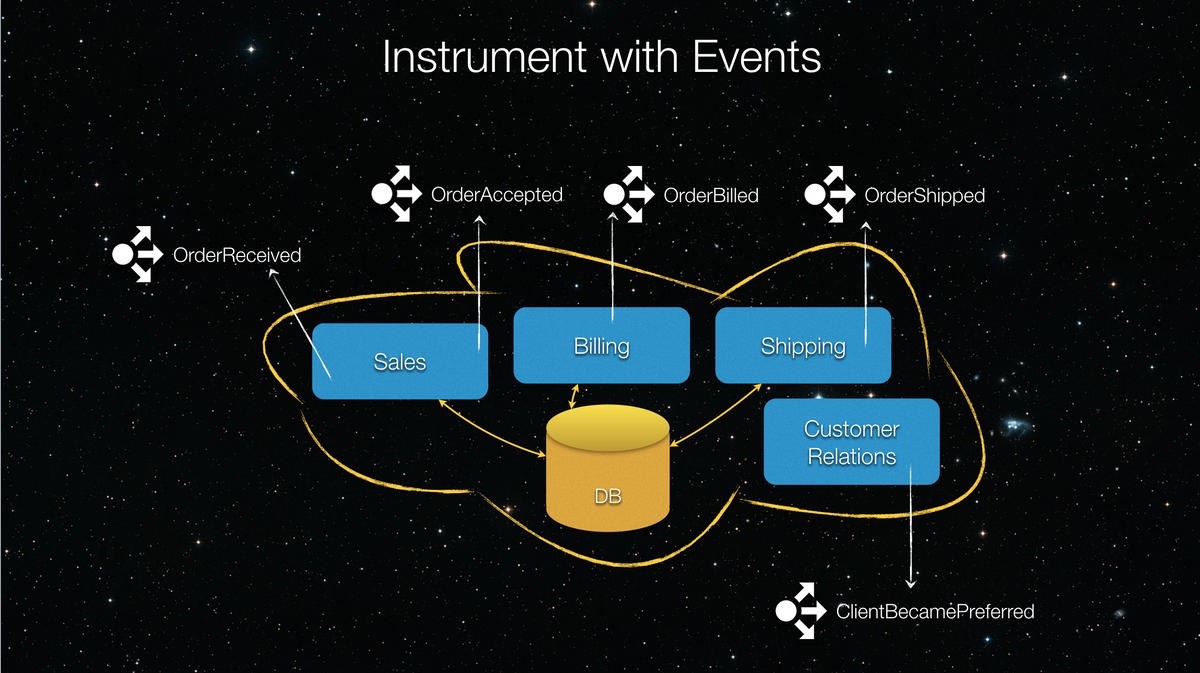
🔗Step 2: Add Your New Feature on the Outside.
Create your feature as a new service that subscribes to the event published by the monolith. When this service receives the event, take the relevant action that needs to occur. This service could also end up publishing an event for processing other downstream business processes.
🔗The Return of the Natural Order
The good news is that you’ve now completely decoupled your new service from the existing monolith. Even better, you can be assured that this new feature is not to going to break other parts of your monolith. You’ve managed to isolate it.
Because the feature is on the outside, it doesn’t fall victim to the old constraints of your monolith. Your service could be written using the latest C# language version making use of the Elvis operator, etc. You can deploy this service without having to stop the monolith service, and now you have all the freedom in the world to write unit tests and integration tests. That land with rainbow unicorns might still be around the corner after all!
Because you’re on the outside of the monolith, your database technology constraints also disappear. You’re now free to select the database technology of your choice to build this feature.
You may not always need a relational database. What you need might be better accomplished with a graph database or a NoSQL database driven by the requirements of your feature.
🔗Strangler Pattern
You can use events to build new features on the outside, but how can you make this monolith obsolete? Again, the answer is with events. You could use different events whose only goal is to start slowly funneling the relevant data from your monolith into your new parts of the system, also written on the outside. You can deploy this new module to production. Since the goal of this module is to gather the needed data from your monolith slowly, running it side by side with your monolith shouldn’t be a problem. Once you’ve shoveled enough data from the monolith database to different storages, you can activate your new feature and remove those redundant parts of the code. Granted, this is a little more intrusive, but you still control the risks.
Martin Fowler talks about a pattern called the Strangler Pattern, where slowly but steadily the monolith starts to lose its relevance and eventually becomes dead.
When you’ve managed to suck enough of the data from the legacy system using these events and funnel them through new smaller services that can have separate databases living on the outside, you’re on target. You can kill your monolith, as does the strangler vine referred to in Martin’s article. With enough time, the monolith might become completely obsolete. That’s how you destroy the Death Star. That’s how you bring balance to the Force.
🔗So what’s the catch?
Since this potentially involves a lot of little services doing their thing based on the single responsibility principle, you could end up with a lot of services. These services will be communicating with other services using messages. It becomes extremely important to audit these messages to have a better handle on what’s going on during debugging. Invest some time in finding the appropriate tools to help you trace these messages. Visualize the flow of messages to get a better understanding of your system from the messaging vantage point to see what works best for you.
🔗In Summary…
Use event-driven architecture style to your advantage when dealing with legacy systems to add visibility to your monolith. Use messaging patterns like publish/subscribe to build new features outside of your monolith. Make sure to evolve your monolith into newer, smaller services, using events from the monolith, to make the monolith lose its relevance.
To start using these design patterns in your current code, and learn how to use the publish-subscribe pattern with NServiceBus, check the samples out.
And finally, stay on target. Destroy your Death Star.
🔗Related Reads:
About the author: Indu Alagarsamy is currently using her force as a developer for Particular Software. She likes to build K-2SOs and other Lego Star Wars construction kits with her kids when she’s not coding or talking about Event Driven Architecture.
 Share on Twitter
Share on Twitter