






A better approach to building retail systems
As retail systems become more and more complex, we need to consider new approaches to system architecture to deal with those challenges.
Learn how, by building a system with NServiceBus, you will be able to:
- Ensure you never lose an order due to a server crash or database deadlock.
- Orchestrate different resources like payment gateways and order fulfillment.
- Say good-bye to batch jobs and instead implement requirements using reactive events.
- Relax on Black Friday, knowing your system will be able to handle the load.
Never lose an order again
The cardinal sin of any retail system is to lose an order. Orders bring revenue, and revenue pays the bills. Incoming orders are the lifeblood of a retail system. Without orders, there is no system.
But in certain all-too-common situations, losing orders is exactly what happens when your customer clicks the Place Your Order button. Why?
If the web server crashes, the order is lost. If the database is down, or in the middle of a failover, the order is lost. If the database experiences a deadlock and chooses your transaction as the deadlock victim, the order is lost.
What do you think users will do after getting a couple of "Oops something went wrong" messages when clicking the Place Order button? Do you really think your users are going to contact support to figure out what the problem is? Or are they going to go to a competitor?
It doesn’t have to be this way.
In a retail system built with NServiceBus, the order coming in over HTTP isn’t subjected to an onslaught of business rules and database transactions. Instead, the information is recorded in a message and put on a queue. That’s it. The customer gets sent to the Thank You page before any backend processing has occurred.
Once the order information is in the message queue, it’s absolutely safe. Another process will handle that message. If anything fails—if a server crashes, if the database is down, or if there’s a database deadlock—the message goes back to the message queue and waits to be processed again.
Watch this video for a better picture of how failures can lead to lost data, lost orders, and lost revenue, and how using NServiceBus will keep your orders safe.
Orchestrate activities between services
Once orders are successfully stored in the system, they need to be processed, paid, and shipped. That requires orchestration between different activities that may not be under our direct control. Clearly, we don’t want to deliver orders that haven’t been paid, or even worse charge the customer and ship nothing.
Database transactions don't help—they are useless when the resources involved are outside of our control. Let’s assume we have a payment gateway and a shipping courier, both of which expose an HTTP API. We cannot enlist those API calls into our database transactions. Still, we need to coordinate and make sure that orders are shipped when paid, not the other way around.
In retail systems built using NServiceBus, we use sagas—essentially message-driven state machines—to model long-running business transactions whose goal is to provide business consistency in an eventually consistent infrastructure.
Using NServiceBus sagas, we can design a shipping policy whose primary purpose is to listen to events announcing that orders have been submitted, and for each submitted order listen to events stating that the same order has been paid. Once both have occurred, it's safe to deliver orders to customers.
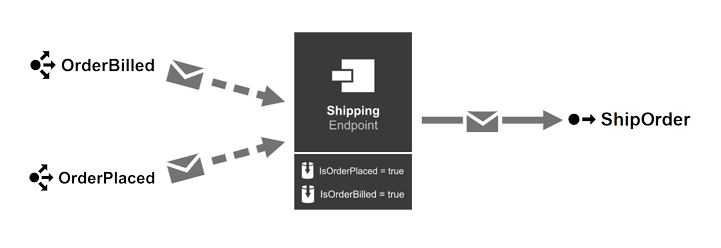
But what if events stating that orders are paid never arrive?
No problem, sagas can handle that. Sagas help you to model time within your business process. By setting a timeout message to arrive in the future, you can check to make sure that the order has been paid within a certain timeframe, and kick off any compensating actions.
Forget about batch jobs
Batch jobs are frequently used (and frequently abused) tools for implementing business requirements by smacking the entire database with a giant hammer in the middle of the night. However batch jobs (or scheduled tasks) commonly suffer from three major ailments:
- The “middle of the night” isn’t long enough. Eventually the job doesn’t finish by morning and continues hammering the database during core business hours.
- Results aren’t immediate. You have to wait until tomorrow to see expected changes take place.
- They’re hard to debug, and they fail randomly in the middle of the night. The person on support duty—and if you’re reading this, there’s a good chance that’s you—has to wake up and figure out how to get it going again.
What if, instead of executing your batch jobs in all-or-nothing manner, you were able chop them into pieces and execute at a steady pace side-by-side with your everyday business?
Consider customer loyalty discounts, where customers who have purchased above a threshold within the last year receive a discount. Querying their entire order history at checkout would be slow. Many times, these requirements are implemented by a batch job that recalculates all customer discounts overnight.
Instead, an NServiceBus saga can define a policy that observes each purchase event, increments a running balance, and updates the customer’s loyalty discount in real time. At the same time, a timeout message is scheduled to deduct the same amount from the running balance after one year.

Now we’ve solved every single problem inherent in batch jobs. Processing takes place throughout the day, and no longer hammers the database to evaluate customers whose state is unchanged. Results are immediately visible. A single customer with unexpected data can’t cause the entire batch job to fail.
If you'd like to read more about this scenario, see our blog post Death to the batch job.
Relax on Black Friday
Traffic spikes are the worst. Sometimes, like on Black Friday, you at least know to expect them, but at other times you have very little time to react. You can either heavily over-provision (and pay for it) or ... let your system fail on the most important day for your business.
Messaging offers a better alternative. It decouples accepting the request from processing the request and erases the constraint of how many requests can be handled concurrently. Excess load simply waits in the queue for its turn to be processed. This makes it much easier to prepare for an increased and unpredictable load.
In traditional design, the user clicks Submit Order and must wait until all data is stored and all processing steps are done. These steps require access to constrained resources—the database, web services, etc.–which make it the most likely to suffer under load, leading to delays and service disruption.
When you add a message queue between the checkout site and backend services, the web request is done once the message is sent, leading to faster responses and more efficient request processing. The backend services are shielded by the queue and can be scaled independently. Whenever more processing power is needed, you can add more backend service nodes, which will all compete to process messages from the queue using the competing consumers pattern.

You can even scale all the pieces at runtime based on performance monitoring data. Tracking the number of items in the queue and the queue’s critical time (the time a message waits in the queue + the time it takes to be processed) gives you a good insight into what’s happening with the system. It makes it possible to predict SLA violations ahead of time and scale out based on current system performance.