





What's new in SQL Persistence 6.1

Business runs on SQL. As popular as NoSQL databases have become, you’d be hard-pressed to find a successful business that isn’t running some flavor of SQL somewhere.
For NServiceBus systems, our SQL Persistence package allows you to use whatever flavor of SQL works best for you, supporting dialects for Microsoft SQL Server, MySQL, PostgreSQL, and Oracle.
SQL Persistence 6.1 is a big release. In it, we now offer a new tool for generating scripts for NServiceBus tables, enable support for SQL Server Always Encrypted, have begun to expand our testing to MariaDB and Amazon Aurora, have solved a problem with ever-expanding outbox storage, and added controls for managing transaction isolation level.
🔗The script
Alfred Hitchcock once said, “To make a great film, you need three things—the script, the script, and the script.” The same can be said for any system that uses SQL to store data.
At build time, SQL Persistence creates SQL scripts as part of its build output which create the tables it needs to store your data. NServiceBus will execute these scripts at runtime if you want (which is very convenient for local development) but to adhere to the principle of least privilege it’s better if your messaging endpoint doesn’t have permission to do that in production.
In SQL Persistence 6.1, we’re introducing a new command-line tool that can generate these scripts anywhere, not just at build time. Just point it at a compiled endpoint assembly, and it will generate the scripts. This gives you the flexibility to generate scripts at build time or any other stage of your CI/CD pipeline.
Install the tool from NuGet:
dotnet tool install -g NServiceBus.Persistence.Sql.CommandLine
Once installed, the sql-persistence command line tool will be available for use:
sql-persistence script {endpoint-assembly} --outputpath={path}
We still generate scripts at build time for you, but now you can do it at any stage to fit in with your deployment pipeline.
🔗Consulting the Oracle
We also fixed a minor issue with the scripts generated for Oracle so that you can use them with SQL*Plus.
Because the structure for every Outbox table is the same, our generated scripts all accept a variable to define the table name. For the Oracle dialect, this was a binding variable named :1. Unfortunately, that name is not a legal identifier which meant the scripts would not work with SQL*Plus, which is one of the more popular tools used to automate scripts against an Oracle database.
This variable is now called :tablePrefix. Our existing code and documentation were already using this name so nothing else needed to change. Now you can use these scripts directly with SQL*Plus.
🔗SQL Server Always Encrypted
SQL Persistence 6.1 now joins our SQL Server Transport in supporting Microsoft SQL Server’s Always Encrypted feature which encrypts columns in database tables without the need to make any code changes.
This means you can encrypt columns in your outbox or saga tables. Outbox tables briefly store the contents of outgoing messages before they are dispatched to a message queue, while saga tables directly contain business data. Either could contain sensitive information that would be better off encrypted.
To use Always Encrypted, you need to make sure that the keys are configured in a trusted key store so that any endpoint that needs access can get them. Once the key management is configured correctly, you can encrypt the columns in the tables that you want to protect.
After selecting the columns to encrypt in SQL Server, the only change needed in the endpoint is to add Column Encryption Setting = Enabled; to the SQL connection string.
For details on setting up encryption, see Support for SQL Always Encrypted in our documentation.
🔗MariaDB and Amazon Aurora
Whenever we make a change to the SQL Persistence code, we run a suite of acceptance tests against our officially supported dialects (SQL Server, MySQL, Oracle, and PostgreSQL) to make sure we didn’t break anything. There are a lot more SQL engines out that than these four, and while we were working on the code we decided to test a few more.
MariaDB is made by the original developers of MySQL, and according to their documentation should function as a drop-in replacement for a MySQL database with the equivalent version. We ran our tests against MariaDB 10.5, and everything passes.
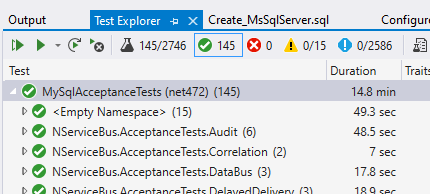
Next up, we took a look at Aurora, Amazon’s database that is offered as a part of their Relational Database Service (RDS). Aurora currently offers two different interfaces. The one they offered at launch is compatible with MySQL, and all of our MySQL tests pass against it.
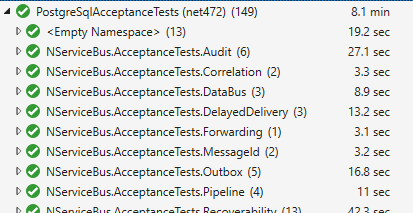
The other was added in October 2017 and is compatible with PostgreSQL. We tried our PostgreSQL tests against it, and those all pass as well.
We had expected that all of these tests would work based on the compatibility claims of each provider, but it is nice to be certain. We don’t (yet) run these tests every time as we do for the main four dialects.
If you’re using (or are planning to use) MariaDB or Amazon Aurora in your project, we’d love to hear from you:
🔗Goldilocks and the outbox records
Recently we heard from a customer that their outbox tables in SQL Server were continuously growing on disk, and the normal cleanup process didn’t seem to be keeping up. The rows were being removed from the database, but the database just kept growing.
At first, we thought that this might be caused by a lack of a clustered index on the outbox table, something that we used to have and removed for performance reasons. With a little bit of testing, we discovered that this was not the root cause.
If the outbox record is small enough, SQL Server will store the data about outgoing messages (an nvarchar(MAX)) in the same page as the rest of the outbox metadata. When we dispatch the messages, we remove the message data, but SQL Server won’t reuse that space, even if the next record would fit. This results in a lot of database pages hanging around, at least as long as the outbox retention period, which is 7 days by default.
If the outgoing message data is large enough, the nvarchar(MAX) column gets stored on its own page. Because we clear out the value after the outgoing messages are dispatched to real queues, this extra page would get cleaned up long before the retention period ends.
This causes page fragmentation, and the solution is to regularly rebuild the outbox table. Yuck!
We started to investigate other options. There is a table hint that we could use to try to force SQL Server to store the message data on another page. This seems like a good solution, but it causes the storage layout to change in other ways, and some Large Object Binary (LOB) pages are permanently introduced. This is a good compromise for SQL Server on-premises, but we found that on SQL Azure these LOB pages appear to be managed differently and their count grows constantly. Not good.
In the end, we decided to try a very simple solution. We know that SQL Server stores the nvarchar(MAX) separately when the message data goes above 8KB. What if we just made 8KB the minimum size of the outbox record by applying padding to it?
It turns out this is the best solution. SQL Server stores the data outside the row but does not introduce LOB pages that grow constantly in SQL Azure.
Ironically, making small records larger results in less space being used! We needed to find a size that was just right.
🔗Managing isolation
We’ve added a new API that allows you to specify the isolation level of outbox transactions.
When you use the outbox, it manages records about messages sent and received in a single database transaction. By default, the isolation level of this transaction is Read Committed, which is good enough for the outbox itself, but not for every business data transaction. To ensure consistency between the transport and your business data, your business operations need to participate in the same transaction. Sometimes, the business logic requires a higher level of transaction isolation.
Consider this example:
select Gross from Orders where Id = 123;
select Net, Tax from Orders where Id = 123;
Normally, Gross should be the same as Net + Tax, but that isn’t always the case. If another transaction modifies these values between statements, the values can change mid-transaction. In the Read Committed isolation level, it is possible because the select locks are released immediately after performing the read.
Previously the only option was to opt out from the outbox and deal with duplicate messages manually. This often leads to very complex code.
The new API allows you to specify the transaction isolation level you need:
var outboxSettings = endpointConfiguration.EnableOutbox();
outboxSettings.TransactionIsolationLevel(System.Data.IsolationLevel.RepeatableRead);
If you’re using the outbox in TransactionScope mode, you can specify the isolation level there too.
var outboxSettings = endpointConfiguration.EnableOutbox();
outboxSettings.UseTransactionScope(System.Data.IsolationLevel.RepeatableRead);
🔗Summary
With this release of SQL Persistence, you can now encrypt data in Microsoft SQL Server, manage your tables more effectively with Oracle, start using MariaDB or Amazon Aurora if you want, and manage your scripts more easily with our command-line tool no matter what flavor SQL you choose.
The new version of the SQL Persistence can be downloaded from NuGet. For more information, check out the detailed release notes for this version, or the SQL Persistence documentation.
 Share on Twitter
Share on TwitterAbout the authors



