





10X faster execution with compiled expression trees
Good software developers will answer almost every question posed to them with the same two words.
It depends.
The best software developers don’t stop there. They’ll go on to explain what it depends on. But this common response highlights a fundamental truth about developing software: it’s all about tradeoffs. Do you want speed or reliability? Maintainability or efficiency? A simple algorithm or the fastest speed?
It gets even worse when you don’t even know exactly what the code is supposed to do until runtime. Perhaps you’re building a runtime procedure from steps stored in config files or a database. You want it to be flexible, but you don’t want to sacrifice performance.
This is exactly what happened during the development of the NServiceBus messaging pipeline. We wanted it to be flexible and maintainable but also wicked fast. Luckily, we found a way to have our cake and eat it too.
By building expression trees at startup and then dynamically compiling them, we were able to achieve 10X faster pipeline execution and a 94% reduction in Gen 0 garbage creation. In this post, we’ll explain the secret to getting these kinds of performance boosts from expression tree compilation.
🔗Stringing behaviors together
As described in our post on the chain of responsibility pattern, the NServiceBus messaging pipeline (represented by the BehaviorChain class) is composed of individual behaviors, each with its own responsibility. Each behavior accomplishes a specific task and then calls the next() delegate in order to pass responsibility to the next behavior in the chain.
NServiceBus behaviors can be used for all sorts of things. NServiceBus contains built-in behaviors both for processing incoming messages (like managing message retries, deserializing messages from a raw stream, or processing performance statistics) and for sending outgoing messages (like enforcing best practices, adding message headers, or serializing messages to a stream). Customers can also define their own behaviors to address any system-wide concern at an infrastructure level rather than in every single message handler. Message signing/encryption, compression, validation, and database session management are all easy to implement with an NServiceBus behavior.
One way to see how these behaviors work is to look at a stack trace when an exception is thrown so we can see all the methods that are involved. Let’s take a look at a stack trace thrown from a simplified version of the NServiceBus pipeline with only three behaviors, where each logical behavior is shown in a different color:

The important thing to note is that the behaviors themselves aren’t the only pieces of code getting executed. As shown in the stack trace, each behavior requires three lines, or stack frames, each of which represents a real method call. Each method called increases the number of instructions the processor must execute, as well as the amount of memory allocated. As more memory is allocated, the garbage collector will be forced to run more often, slowing the system down.
In this case, each behavior requires two extra stack frames after its own Invoke(context, next) method (as shown above) in order to call the next behavior. The eight stack frames from BehaviorChain are all pure overhead, and they vastly outnumber the three stack frames from the actual behaviors.
So, in this version, we have 13 total stack frames, with three per behavior. A real NServiceBus pipeline would have many more behaviors, so it’s important to focus on the per-behavior cost. At first glance, three may seem to be an acceptable amount of overhead in order to be able to dynamically compose the behaviors together. After all, software is about tradeoffs. In return for just a bit of overhead, we get small, maintainable behaviors and an extensible pipeline where it’s easy to add, remove, or reorder individual steps.
🔗It gets worse
For NServiceBus 6, we wanted to improve how the pipeline is composed from its individual behaviors so that it would be even more flexible and maintainable. We also wanted to fix some problems users were having getting their own custom behaviors registered in the correct position. What we found was that adding in the additional pieces to create that flexibility was also adding significant overhead to pipeline execution, and that overhead was adversely impacting the speed at which NServiceBus could process messages.
Although each behavior in NServiceBus is sufficiently isolated, composing them together turned out to be problematic in version 5. Adding a new behavior involved an API using RegisterBefore(stepName) and RegisterAfter(stepName), with step names essentially being “magic strings.” It was too easy to create a behavior that wouldn’t end up being registered in the right location in all cases, given that it could only define itself relative to other behaviors—some of which might not always exist.
To address this, we added the concept of pipeline stages in version 6. Behaviors would be grouped into “stages,” one for each type of context—either the IncomingPhysicalMessageContext, the IncomingLogicalMessageContext, or the InvokeHandlerContext. Within each of these stages, the exact order of behaviors would not matter. This removes the problem of getting behaviors registered in the right order, as execution order within a pipeline stage no longer matters.
Within this pipeline, each stage would be separated by a special behavior in the framework called a connector, which would be responsible for transitioning between them. For example, the PhysicalToLogicalConnector is responsible for changing the IncomingPhysicalContext containing the message as a raw stream into an IncomingLogicalContext containing a fully deserialized message object.

Now, the thing is that the stage connector is also a step in the pipeline, which means it will also increase the total depth of the stack trace. This, in turn, causes even more performance overhead. What’s worse, a few extra pieces (a generic BehaviorInvoker and a non-generic BehaviorInstance) are required to deal with the realities of generic types in C#, further deepening the stack trace.
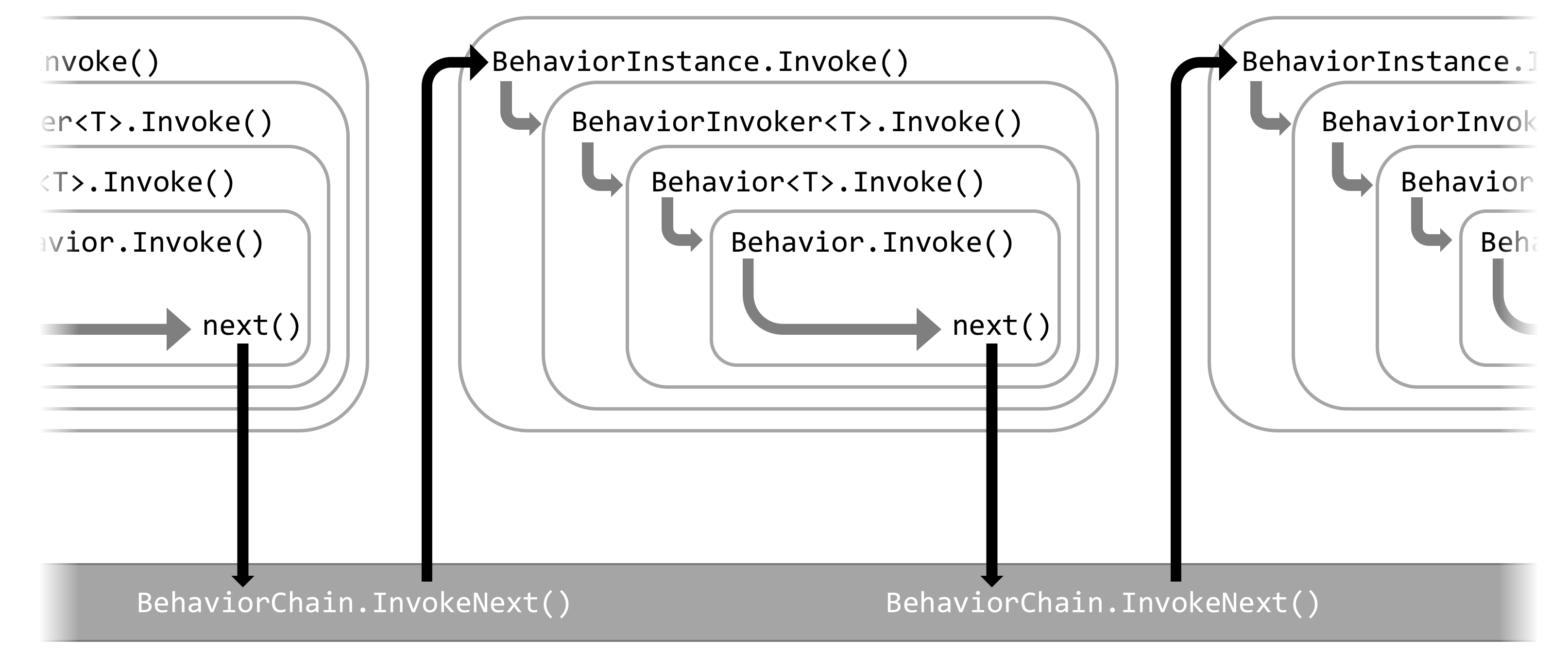
Let’s compare the previously shown NServiceBus 5 stack trace to one using the stage and connector concepts introduced in NServiceBus 6. In the previous stack trace, there are three behaviors. In the interest of brevity, we can eliminate one behavior and replace it with the PhysicalToLogicalConnector mentioned previously so that there are still the same number of total behaviors:

Stages and connectors clearly come with a cost. The stack trace grew from 13 stack frames to a whopping 26! Notice how many more stack frames are required per colored behavior, compared to just three each in the earlier example. Behaviors now require seven stack frames each, while connectors are only a bit cheaper, requiring five frames. The dramatic increase in overhead doesn’t bode well for pipeline performance.
Adding async/await to the mix would increase the execution overhead even more. With that, you can get some truly monstrous stack traces.
🔗The need for speed
By adding stages and connectors to the pipeline, we successfully reduced API complexity for NServiceBus 6. But in doing so, we added so many additional layers that the performance of the pipeline suffered.
This is a classic software tradeoff between maintainability and efficiency. Which did we want? Well, we really wanted both.
If all we cared about was performance, we’d just hard-code the entire pipeline. Instead of iterating through a list of behaviors and doing backflips with generic types to invoke each behavior with the correct context, we’d write code that looked like this:
behaviorOne.Invoke(contextO, context1 => {
physicalToLogicalConnector.Invoke(context1, context2 => {
behaviorTwo.Invoke(context2, context3 => {
invokeHandlersBehavior.Invoke(context3, context4 => {
// End of pipeline
});
});
});
});
From a performance perspective, this is as good as it gets. But then, if the pipeline was statically defined, there would be no way to insert new behaviors or modify the pipeline in any way.
So, we decided to try to find a way to use behaviors for their flexibility but then compile that pipeline down to replicate the optimized, hard-coded version shown above at runtime.
🔗Compiling Expressions
In NServiceBus 6, we now compile the entire behavior chain into a single delegate containing each behavior directly calling the next, just as if we had hard-coded it. All of this is possible thanks to the magic of the Expression class.
We start by finding all of the registered behaviors and arranging them in order, according to the pipeline stage they target. Starting at the end of the list, we use reflection to get the MethodInfo corresponding to the behavior’s Invoke(context, next) method.
At the heart of the optimization is this chunk of code, which builds a lambda expression from each pipeline step and then compiles it to a delegate.
static Delegate CreateBehaviorCallDelegate(
IBehavior currentBehavior,
MethodInfo methodInfo,
ParameterExpression outerContextParam,
Delegate previous
{
// Creates expression for `currentBehavior.Invoke(outerContext, next)`
Expression body = Expression.Call(
instance: Expression.Constant(currentBehavior),
method: methodInfo,
arg0: outerContextParam,
arg1: Expression.Constant(previous));
// Creates lambda expression `outerContext => currentBehavior.Invoke(outerContext, next)`
var lambdaExpression = Expression.Lambda(body, outerContextParam);
// Compile the lambda expression to a Delegate
return lambdaExpression.Compile();
}
Here’s the really important bit: You have to start at the end of the pipeline because the lambdaExpression.Compile() method only compiles down one level—it is not recursive. Therefore, if you assembled all the lambda expressions together and tried to compile it from the outermost level, you would not get the performance boost you were seeking.
Instead, each compilation is like a tiny fish getting eaten by a slightly larger fish. As you continue to work backward toward the beginning of the pipeline, each compiled fish gets eaten by successively bigger fish, until you have one very large fish that represents a fully compiled expression tree of the fully composed pipeline.
With all the levels of abstraction for the “glue” holding the pipeline behaviors together optimized away, the compiled delegate looks and behaves just like the hard-coded example above. Already this is a big increase in pipeline performance.
🔗But wait, there’s more!
Because we had gone to the trouble of profiling memory allocations in the pipeline, we were able to squeeze even more performance out of it by changing how we implement our own internal behaviors.
Although there’s a nice base class that simplifies the creation of behaviors, specifically to make life easy for our users, we deliberately avoided using it for our internal behaviors and implemented a slightly more complex interface instead. That saved an additional allocation of the base class as well as an extra couple of frames per behavior.
With that additional optimization, let’s take a look at what the stack trace looks like now:

At only 10 stack frames (compared to 26, previously), we’re now running a much tighter ship—even more efficient than the 13 frames before we added stages and connectors. Not only are there fewer methods in the stack, but we’re also creating a lot fewer objects when processing each message. This means there’s less memory allocated, which means there’s less pressure on the garbage collector as well.
🔗Results
Before deciding to include this optimization in NServiceBus 6, we ran a slew of benchmarks against it to see how it would perform. You can see the full details in the pull request. However, here are some of the highlights:
- A real-life call stack, based on an example of the outgoing message call stack when publishing a message, was reduced from 113 lines to approximately 30 lines for a 73% improvement in call stack depth compared to the non-optimized version. With no infrastructure overhead, the change results in a dramatic size reduction for error messages, as well as call stacks that are easier to read and debug.
- There was up to 10X faster pipeline execution for the cases where no exceptions were thrown and the pipeline completed successfully.
- There was up to 5X faster exception handling, even in cases where an exception is thrown at the deepest level of the call stack. When an exception is thrown, it matters quite a bit how deep in the pipeline it’s thrown from. An exception thrown earlier in the pipeline will not have to bubble up as far and will be handled even faster.
- We saw a 94% reduction in Gen 0 garbage creation with the dramatic reduction in calls and allocated objects.
🔗Summary
With the improvements to the behavior pipeline in NServiceBus 6, it’s easier than ever to create and register your own custom pipeline behaviors to handle system-wide tasks on an infrastructure level. But rather than accept additional overhead to make the API improvements possible, we’ve supercharged the pipeline so it can process your messages faster and more efficiently than ever before.
This easy extensibility is one of the capabilities of NServiceBus that we’re most proud of. If you’d like, you can find out how to build your own NServiceBus behavior. Or if you’re new to NServiceBus, check out our NServiceBus step-by-step tutorial to get started.
🔗Similar success stories
- Automapper 5.0 speed increases
- How we did (and did not) improve performance and efficiency in Marten 2.0
About the author: Daniel Marbach is an engineer at Particular Software who has a very particular set of skills. Skills he has acquired over a very long career. Skills that are a nightmare for resource hogs everywhere. If you use LINQ where it’s not necessary, he will look for you, he will find you, and he will…submit a pull request.
 Share on Twitter
Share on Twitter