





A new era for MSMQ scale-out
This post is part of a series describing the improvements in NServiceBus 6.0.
Scaling out a web server is easy. All you have to do is stand up a bunch of web servers behind a load balancer like HAProxy and you’re covered. Unfortunately, it hasn’t been quite as easy to scale out MSMQ-based NServiceBus systems.
That is, until now.
But first, let’s take a look at how things currently work. The MSMQ Distributor component uses roughly the same model as a load balancer, but for MSMQ messages rather than HTTP requests. The main difference is that the distributor can hold messages in a queue, waiting for an available worker to be ready to process it.
The thing is, setting up the distributor so that you can scale out an MSMQ endpoint is quite a bit more complicated than scaling out when using HTTP load balancers or even a broker-based message transport like RabbitMQ or Azure. In those transports, you can scale out simply by adding another instance of an endpoint1. Granted, the other message transports that use a centralized broker have to worry about the uptime and availability of that broker, whereas MSMQ is inherently distributed and doesn’t have to worry about a single point of failure.
But it would still be nice if it were easier to scale out MSMQ.
🔗Anatomy of a Distributor
The distributor receives messages from senders and passes them on to various worker nodes. Just like regular load balancers, the distributor doesn’t know how to process messages; it only routes them to the available workers. Since web requests need to be processed right away, they are all assigned to a web server immediately. But MSMQ messages can wait in a queue. For this reason, the distributor doesn’t assign a message to a worker until the worker node tells the distributor that a thread has finished processing a message and is now able to handle another one.
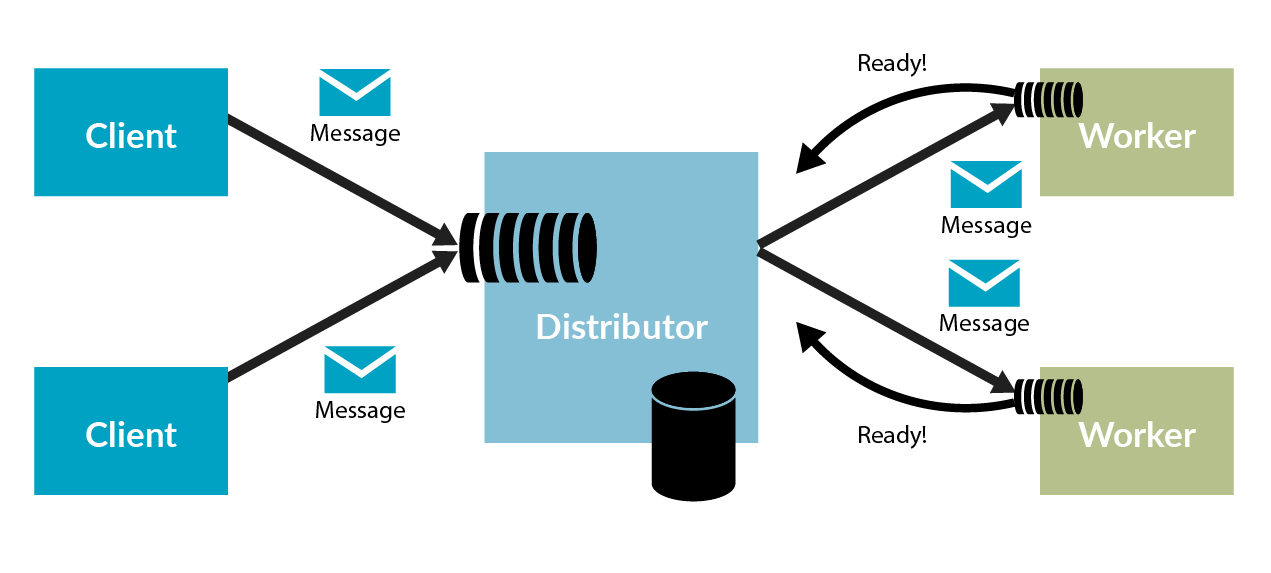
When a worker checks in, the distributor notes the availability in its own storage. That way, it can route incoming work items to workers that are ready for them. This requires extra messages, which can create a certain amount of overhead.
Just as it’s possible to overwhelm a normal load balancer, there are only so many messages per second that a distributor can handle. At some point, the distributor will hit a maximum limit, and, unfortunately, it wasn’t designed to be scaled out. For simple tasks that aren’t CPU or I/O intensive, adding more workers isn’t effective because the distributor becomes the bottleneck. The single-node distributor simply can’t get messages to the workers fast enough.
The distributor is also a single point of failure for the messages it handles. It should really be set up for high availability, the way load balancers are. Load balancers are usually made highly available through a kind of active/passive configuration between two servers. The two servers monitor each other through heartbeats on a private network connection, with the standby server ready to jump into action when it detects the primary server is not responsive. Unfortunately, this is a bit harder to do for the distributor, since MSMQ needs to be made highly available as well.
Finally, you need to plan to have a distributor in place for each endpoint before you can scale it out. It’s a lot easier with the other message transports. Take, for instance, the RabbitMQ transport. Once you set up the message broker for high availability, any endpoint can be scaled out just by standing up a new worker. When using the distributor, every scaled-out endpoint requires additional work and reconfiguration.
🔗Removing the bottleneck
NServiceBus Version 6 introduces a new feature called sender-side distribution to replace the distributor as a method to scale out with the MSMQ transport. Before, each worker would check in with its distributor. This way, the distributor was the only actor that knew where all the workers were located. Now, with sender-side distribution, the knowledge of where endpoint instances are deployed gets distributed throughout the system so that all endpoints can collaborate with each other directly.
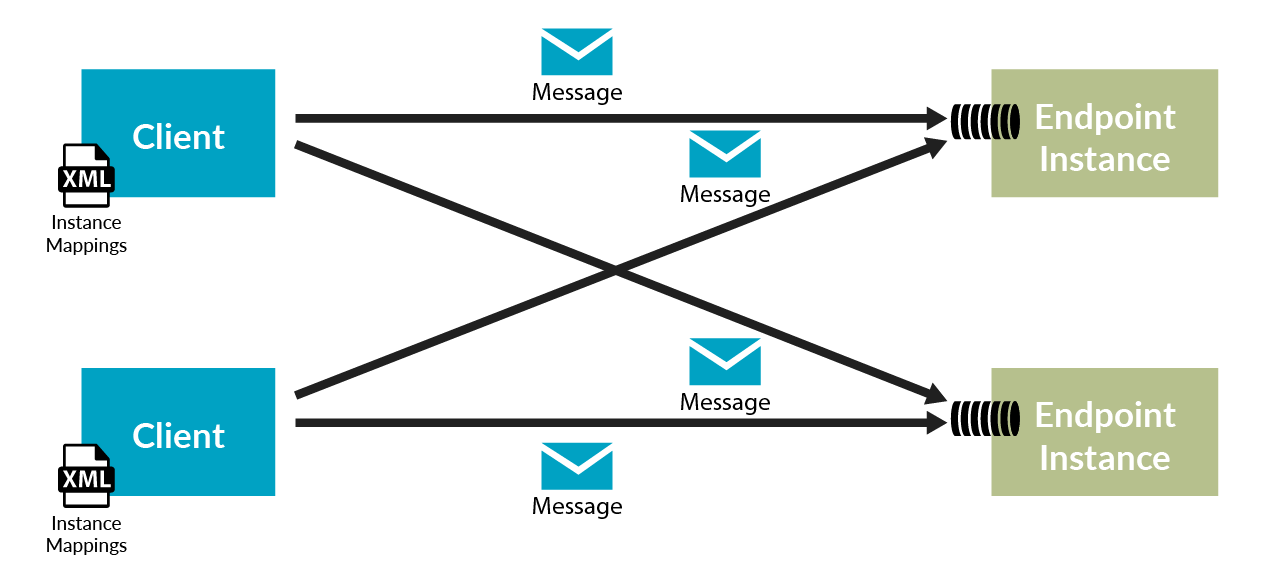
With sender-side distribution, the routing layer at the sending endpoint knows about all the possible worker instance destinations upfront. This makes it possible to rotate between destinations on every message that’s sent. It’s as if a DNS server returned all possible IP addresses for a domain, and the browser rotated between them on different requests. There’s no need for another piece of infrastructure (e.g., a load balancer or even a DNS server) in the middle. This autonomy results in a big payoff for messaging-based systems.
With the distributor removed as a single choke point, scaling out pays off even for small tasks. There’s no limit to how many processing nodes can be used and no diminishing returns from adding more. The infrastructure doesn’t have to be planned as carefully. Even if you didn’t plan for high load from the start, it’s easy to add more instances to handle the work without needing to set up a distributor first. High availability is no longer an issue and Windows Failover Clusters are not needed because there is no distributor acting as a single point of failure.
This new topology enables ultra-wide scalability, as you could conceivably stand up hundreds of nodes to collectively process a ridiculously high number of messages per second. Messages would be spread out among all these instances without any centralized actor needed to coordinate anything.
The default message distribution strategy uses a simple round-robin algorithm, rotating through the known endpoint instances for each message sent. However, you can plug in your own custom implementation2.
The configuration for sender-side distribution could not be simpler. One XML file defines each endpoint name and its collection of instances:
<endpoints>
<endpoint name="Sales">
<!-- Scaled-out endpoint -->
<instance machine="Sales1"/>
<instance machine="Sales2"/>
</endpoint>
<endpoint name="Shipping">
<instance machine="Shipping1"/>
</endpoint>
</endpoints>
Each endpoint instance can have its own instance mapping file, or all endpoints can read the same file from a centralized file server so that changes to system topology can be made in one convenient location. The new routing features would also allow you to integrate directly with service discovery solutions like consul.io, zookeeper, or etcd. Combined with these tools, the routing table would dynamically update as soon as endpoint instances either become available or are removed.
Of course, we won’t force you to use this new distribution scheme. The distributor is still supported in legacy mode in NServiceBus Version 6 to ensure backward compatibility. However, we’re sure you’ll like the sender-side distribution a whole lot more once you give it a try.
🔗Summary
For the MSMQ transport, sender-side distribution reduces the amount of upfront infrastructure planning you need to do. One shared file can keep all endpoints updated on what instances can process messages. Adding and removing endpoint instances can be done without the need to reconfigure the topology to make room for a distributor. Just add more instances when you need them, and remove them when you don’t.
You won’t need a distributor in a Windows Failover Cluster anymore. To ensure high availability, simply add two or more instances of every endpoint. It’s that simple.
Simpler is better. So go ahead, get rid of the distributor and use sender-side distribution instead.
🔗Footnotes / Further Reading
-
1 On centralized broker-based transports, scaling out is accomplished using the competing consumers pattern.
-
2 Check out our fair load distribution sample for an example of a routing strategy that keeps the queue length of all load-balanced instances equal.
-
Documentation: Scaling out with sender-side distribution
 Share on Twitter
Share on Twitter