





UI composition - the blind spot of distributed systems

When architecting a distributed system, it’s easy to get caught up in the excitement of all the cloud backend services available to us. Azure Service Bus! AWS Lambda! CosmosDB! We spend a lot of time decoupling all our backend with microservices, each with their own responsibility and stack and so forth, that we often forget: the front-end has to talk to all of these services. But it can be decomposed into components just as easily as the back-end services can. Here’s a story of how we did it.
I was at a customer site, and we were analyzing their business processes with the intent of building a new component of their system. The customer is basically a logistics company, whose responsibility is to deliver goods on behalf of their customers and, when applicable, to charge the recipient of the goods for the delivery and handling process. During this discussion, the accounting manager raised an interesting issue.
One of the internal departments is responsible for monitoring the overall state of customers’ orders. This department is currently overwhelmed by the amount of work required to gather the information they need. They end up wasting a lot of time gathering this information instead of doing their actual work.
The manager and I began to discuss options for removing all of this friction. We began to talk of building a single front-end application capable of aggregating all of this information.
What we immediately realized is that there seems to be no canonical guide to designing UIs that retrieve and aggregate data from different sources. Sure, there are a lot of resources and discussions about Distributed Architectures, Domain Driven Design and the process related to correctly identifying bounded contexts; finding guidance for designing your services and their interactions is not a problem. But when it comes to designing an aggregator UI, there isn’t much. As a result, it is really easy to create a UI that couples otherwise unrelated data and services. Or, as in this scenario, it’s easy to couple services owned by different departments or even by third parties.
🔗Client side UI Composition
UI composition work should be done in the client-side code. This is the only place that can connect the dots and glue together pieces of data coming from different endpoints. Composing data at the client is, in my experience, a two step process:
- Compose the client side
ViewModel; - Display the
ViewModel;
The technology used for the composition is not that important. Using JavaScript is much easier to start with, due to the dynamic nature of the language. The same thing that introduces long-term maintenance challenges e.g. when trying to debug errors. Using C#, in a strictly typed manner (so no use of dynamic keyword), could help here. That said C# can introduce tons of boilerplate code for something that, in JavaScript, is very straightforward.
The following concepts apply also to a pure MVC client application in which all the composition, applying the same techniques, is done server-side before rendering HTML pages.
🔗Assumptions and requirements
Let’s assume that data have identifiers, are segregated, and are owned by services that expose a way to consume them. An example consumption mechanism might be an HTTP endpoint.
For example, we can try to model the following requirement:
As a user I want to view the list of customers where, per customer, there is a summary of order status and payment status.
We have 3 different services involved in the aforementioned scenario: registry, orders and accounting. The initiator of the orchestration is the registry, because the user is querying for customers, but in this case registry is just a detail.
The following picture shows a UI mockup outlining information sources and responsibility:
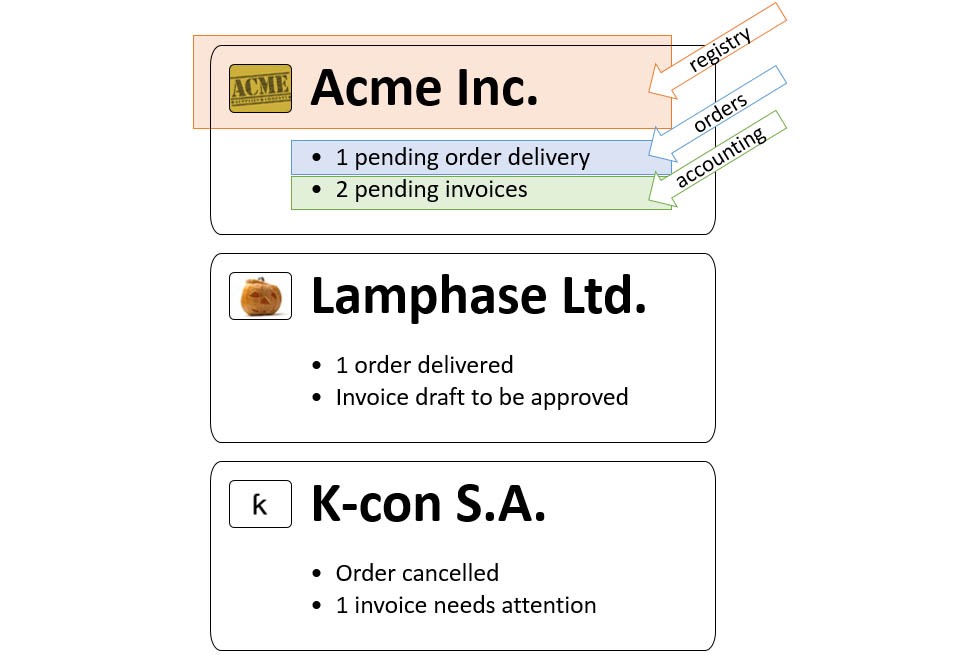
The goal is to be able, given the customer id, to query the registry system, the order system, and the accounting system to retrieve data related to a given customer (or a list of them), and then compose the results into a single UI component.
🔗Client side composition process
At the client side we have components – JavaScript classes for example – that belong to each service. In the case of third parties, the components are an anti corruption layer (ACL) that acts as a proxy, and that behaves as a facade to those services. These components are deployed to the client application by each service.
At client application start-up time, each of the components registers itself, with an infrastructure component, to provide composition services for a given scenario. I’ll call this infrastructure component the Composition Gateway.
As the user interacts with the application two things happen:
🔗ViewModel Composition
When the application needs to retrieve either a list of customers or a single one given its id, the application queries the Composition Gateway instead of going directly to the remote endpoints. Next, the Composition Gateway notifies all the registered components, also known as requests handlers, about the incoming request and provides these components with an empty ViewModel to be filled with data. Each component that is interested in participating issues the corresponding HTTP request to its respective backend endpoint. The Composition Gateway then receives a callback (an async Task in the .NET world) that will be used to wait for all the actors to complete their respective requests.
As each request to the backend endpoints is completed, the components fill the provided empty ViewModel with the retrieved data (a JSON object, in this case, is perfect). Finally the Composition Gateway returns the ViewModel to the UI-composition component of the system.
The following picture shows a diagram of the ViewModel composition process:
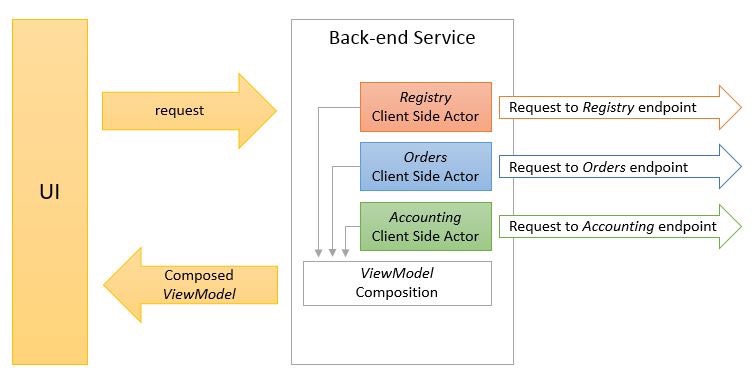
One important thing to highlight is that it is a
ViewModelrather than just a model. AViewModel, inMVVMterms, has both data and behaviors. It is not a simpleDTOwith no business logic. Endpoints may returnDTOsthat will be mapped to client sideViewModels.
🔗ViewModel Templates
The previous step in this composition pipeline returned a composite ViewModel that represented everything the client application needs to display. When it is time to display it, the client application cannot make any assumptions about the shape of the returned data. Otherwise, we are coupling services at the last step, and thus preventing UI modules from changing or evolving without breaking the entire UI.
At this level we can leverage a template engine. WPF has the amazing DataTemplate concept. Building one for Angular is not that complex if you start from the ngTemplateOutlet directive. And ASP.Net MVC has partials, model templates, and view components.
What happens is that at the UI level (in the HTML markup for example) we can bind the composite ViewModel with the element, in the elements tree, that will display it. The only assumption unique to the root element is that its ViewModel is a sort of dictionary that can be enumerated. The root element will enumerate the sub-ViewModel(s) and for each of them it will load a specific template to display the corresponding data.
NOTE: Templates and all graphical representations are the responsibility of the
Brandingservice; business-centric services shouldn’t own model templates.
The mapping between the ViewModel and its template can be made by convention or by an actor in the composition pipeline that can put some logic in place. This logic will decide which template to use to display a specific piece of data in a specific scenario.
The only responsibility of the root element is to organize templates in the UI, so the root element is a sort of a “grid” with holes that will be filled at run-time by the rendered templates. The root element owns the design of the grid, not the content design and not how it is displayed.
Since they are rich ViewModels each one can now be rendered in the UI as preferred without having any dependency on other pieces of the system. If it is required I use events to bring the power of publish/subscribe even at the UI level; when something happens in some portion of the UI a “client” event is published so that other portions can react accordingly.
🔗A couple of weeks later…
The very first version of the process monitoring system was deployed to a well-known set of users, triggering an extensive user acceptance test process.
Following the above guidance, the accounting department succeeded in solving their daily issues and, from a technical point of view, they were able to build a composite UI with a really thin dependency on the services exposing the required data. This will allow the entire system to evolve as needed to handle the inevitable behavior changes of service providers. And this evolution can happen without causing the system’s developers endless headaches.
If you’re interested in more information about ViewModel composition, check out the ViewModel Composition series on my blog that describes more advanced concepts.
 Share on Twitter
Share on TwitterAbout the author
