





RPC vs. Messaging – which is faster?

Sometimes developers only care about speed. Ignoring all the other advantages messaging has, they’ll ask us the following question:
“But isn’t RPC faster than messaging?”
In place of RPC, 1 they may substitute a different term or technology like REST, microservices, gRPC, WCF, Java RMI, etc. However, no matter the specific word used, the meaning is the same: remote method calls over HTTP. So we’ll just use “RPC” for short.
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. But the answer isn’t that simple. It’s less of an apples-to-oranges comparison and more like apples-to-orange-sherbet.
Let’s take a look at the bigger picture.
🔗Why RPC is “faster”
It’s tempting to simply write a micro-benchmark test where we issue 1000 requests to a server over HTTP and then repeat the same test with asynchronous messages. But to be fair, we also have to process the messages on the server before we can consider the messaging case to be complete.
If you did such a benchmark, here’s an incomplete picture you might end up with:
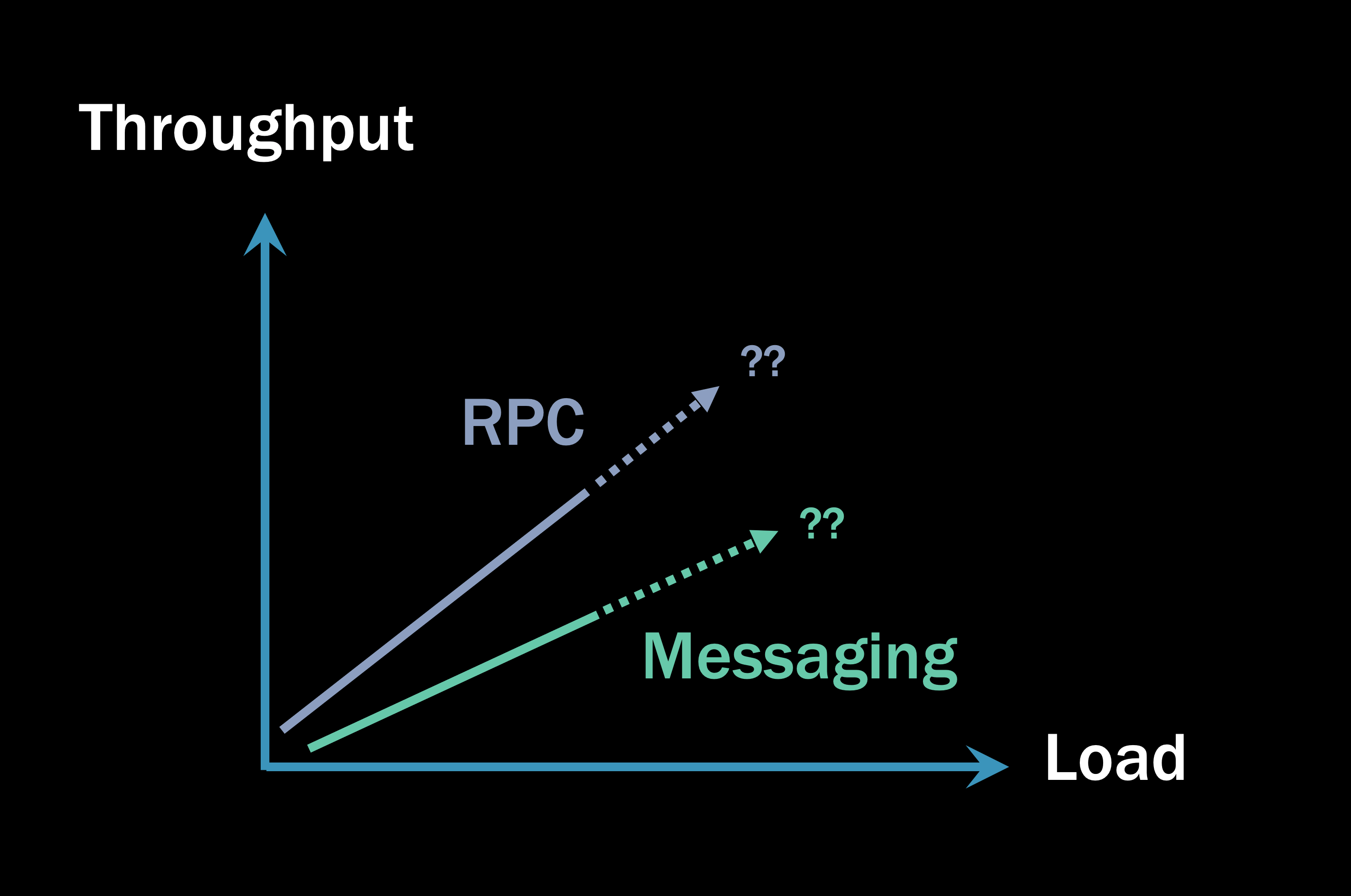
Initially, the messaging solution takes longer to complete than RPC. And this makes sense! After all, in the HTTP case, we open a direct socket connection from the client to the server, the server executes its code, and then returns a response on the already-open socket. In the messaging case, we need to send a message, write that message to disk, and then another process needs to pick it up and process it. There are more steps, so the increased latency is easily explained.
But that’s just a micro-benchmark and doesn’t tell you the whole story. Anyone who shows you a graph like that and says “RPC is faster” is either lying or selling you something. 2
🔗Threads and memory
Unfortunately, the web servers serving your RPC request won’t scale linearly forever, which becomes a big problem.
What you typically see nowadays in a “microservices architecture” using RPC 3 is not a single RPC call, but instead, one service calling another service, which calls another service, and so on. Even a service that doesn’t turn around and call another service usually has to do something like talk to a database, which is another form of RPC.
What happens with threads and memory when you’re doing these remote calls?
When you begin a remote call, any memory you had allocated needs to be preserved until you get a response back. You may not even be thinking about this as you’re coding, but whatever variables you’ve declared before the RPC call must retain their values. Otherwise, you won’t be able to use them once you have your response.
Meanwhile, the garbage collector (or whatever manages memory in your runtime environment) is trying to make things efficient by cleaning up memory that’s not used anymore.
Garbage collectors are designed under the assumption that memory should be cleaned up reasonably quickly. So in relatively short order, the garbage collector will perform Generation 0 (Gen0) collection, in which it will ask your thread, “Are you done with that memory yet?” Nope, as it turns out, you’re still waiting for a response from the RPC call. “No problem,” the garbage collector will say, “I’ll come back and check with you later.” And it marks that memory as Generation 1 (Gen1), so it knows not to bother your thread again too soon.
Around ~50,000 CPU operations later, the garbage collector will come around for a Gen1 memory collection. This is a long time in terms of CPU cycles, but it’s maybe about 50 microseconds for us humans, which isn’t much at all. It’s also not a long time in terms of a remote call, which is way slower than a local function execution. “Are you done with that memory now?” Your thread is shocked—doesn’t the garbage collector understand how long remote calls take? “No problem,” the collector says, “I’ll come back later.” And it marks your memory as Gen2.
The actual timings of the garbage collector’s activity will vary on a lot of things, but the point is that your memory can be put into Gen2 before your RPC call even completes. This is important because the garbage collector doesn’t actively clean up Gen2 memory. So even if you get a response back from the server and your method completes, your Gen2 memory may not be cleaned up except for IDisposable objects.
Regular memory just sits there in Gen2. You essentially have a minor memory leak when you’re invoking remote calls if those calls take enough time to come back. This memory accrues until the system is under enough load that it can’t allocate additional memory anymore.
Then the garbage collector says, “Uh-oh, I guess I better do something about this Gen2 memory.”
🔗Stop the world
This is where the throughput of an RPC system starts to go off the rails.
The garbage collector has already tried to clean up Gen2 memory twice, and it’s obviously being actively used by the thread. So the garbage collector’s only choice is to suspend all the currently-executing threads in the process to clean up the Gen2 memory.
That’s when the throughput of your RPC system starts to look like this:
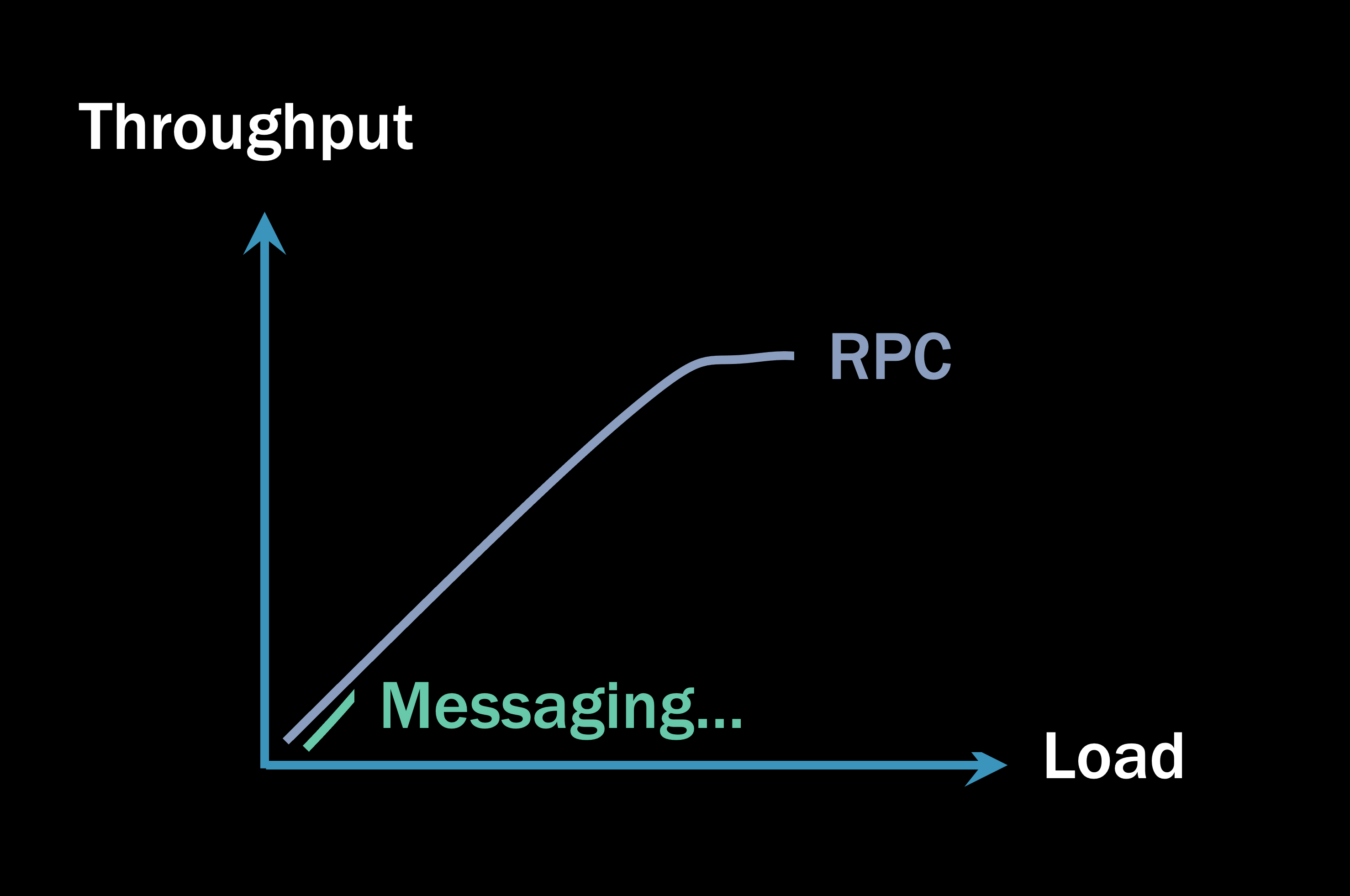
The scale on the Load axis is expanded beyond a micro-benchmark now. As the garbage collector starts suspending the threads of your process to clean up memory, all the clients waiting for a response from you now have to wait longer.
This creates a dangerous domino effect. As one part of your system gets slower, it responds more slowly to its clients, which means their memory goes into Gen2 faster, which means their garbage collector will suspend their threads more frequently, which means their clients must wait longer…you can see where this is going. The deeper your RPC call stacks are from one microservice to the next, the more accumulated memory pressure you have. And the more memory pressure you have, the more likely it is that you will find yourself in this sort of situation:
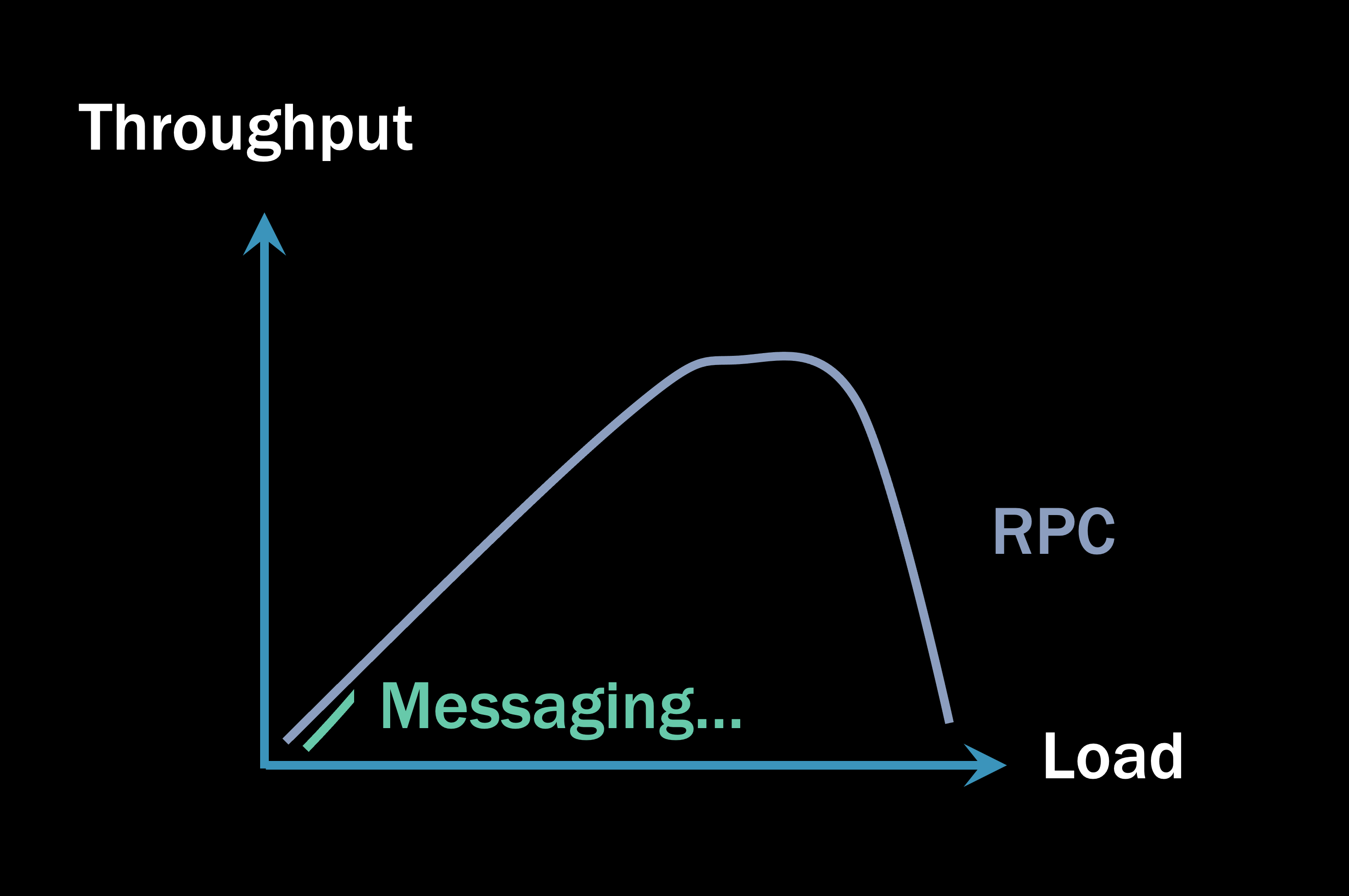
On the right side of the graph, the process can’t spin up more threads to handle additional incoming requests because it ran out of memory. Meanwhile, you, the client, are receiving the exception “Connection refused by remote host.” You’re getting a response, but the server is saying, “Look, I’m too busy. You’re going to have to come back later.” It can’t afford to spin up more threads and is load shedding, which is the only mechanism an RPC system has to handle the excess load.
If all you have is a single client and a single server, this usually isn’t going to be a big deal. But the more small moving parts that you have, the more fragile the system will be.
🔗Load in messaging systems
Systems built on messaging, under load, will usually exceed the throughput of an RPC-based system.
Systems built on message queues don’t do load shedding like RPC systems because they have storage on disk to store incoming requests as they come in. This makes a queue-based system more resilient under a higher load than an RPC system. Instead of using threads and memory to hold onto requests, it uses durable disks. As a result, many more messages can be sitting in queues even while the system is processing at peak capacity.
This is why it’s like apples and orange sherbet to compare RPC and messaging using a micro-benchmark like at the beginning of this article: If you’re allowed to throw away whatever requests you feel like, it’s not a fair comparison. Messaging doesn’t do that.
In a messaging-based system, there’s usually no waiting around for responses from other microservices. I receive a message, I write something to my database, and maybe I send out additional messages, and then on to the next. Message-based microservices are running very much in parallel with each other. With no waiting, message processing under load will scale up to a certain point, based on a number you configure: the maximum number of concurrently processing messages. 4
With all the parallel processing and no waiting, the messaging architecture generally overtakes the RPC under load, resulting in a higher (and more importantly, stable) overall throughput.
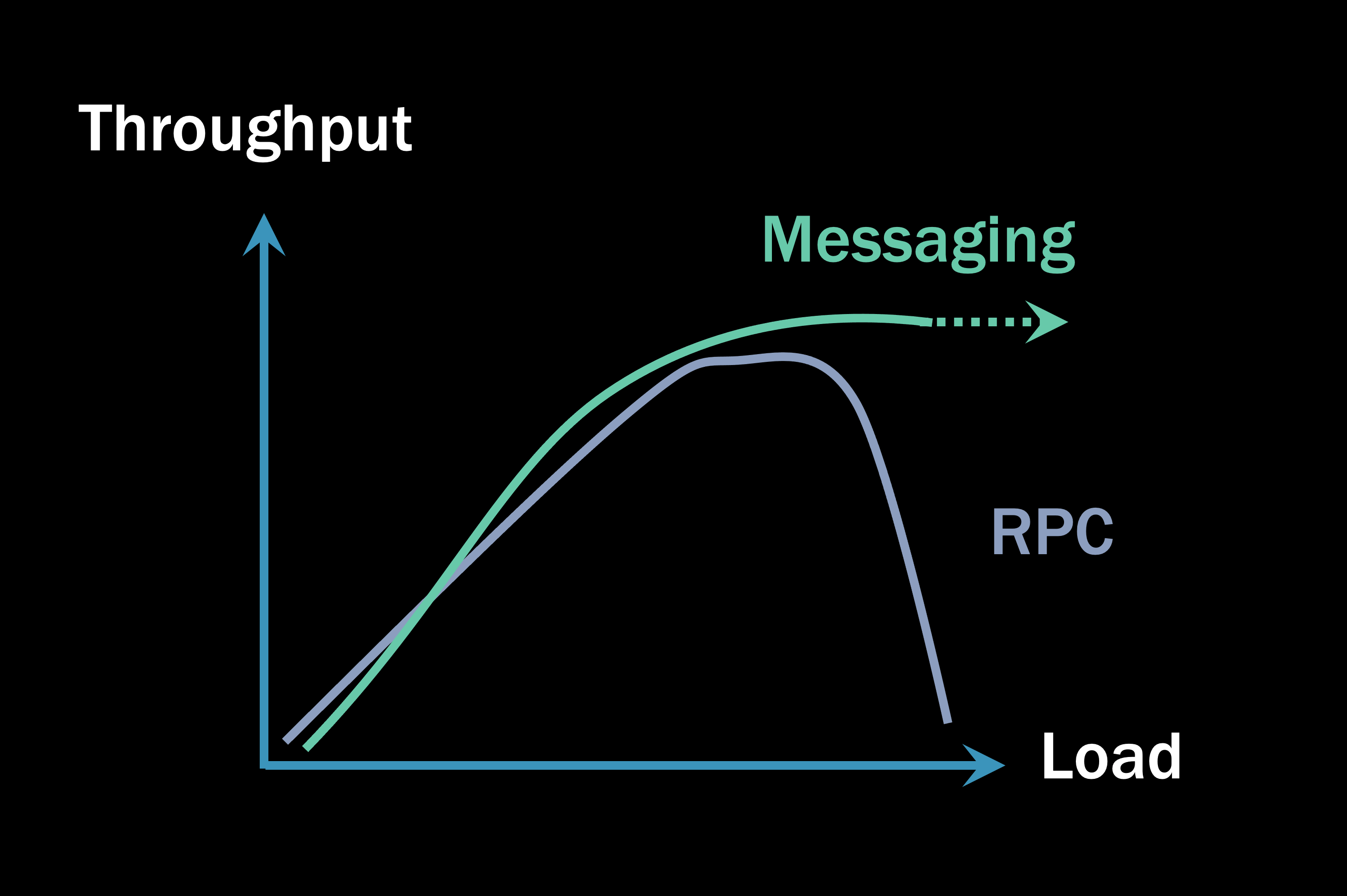
How much higher throughput? It depends very much on the system, how you designed it, whether the database is the bottleneck, and a million other factors. But usually, the async processing model results in a more parallel-processing result, resulting in higher throughput for your system than the synchronous blocking RPC model.
🔗Summary
Anytime we use a synchronous RPC model, there’s always a risk of an “epic fail” scenario. There’s always a risk that an RPC system will start running out of threads and memory, the garbage collector will start suspending threads more frequently, the system will do more housekeeping than business work, and soon after, it will fail.
Systems built on asynchronous messaging won’t fail like that. Even if the RPC system doesn’t fail, the messaging sytem will usually exceed the throughput of an RPC system.
If you’d like to learn how to build messaging systems this way, join me for a live webinar Live coding your first NServiceBus system where I’ll show you all the fundamental messaging concepts you need to understand to build an effective distributed system using messaging instead of relying on RPC communication.
 Share on Twitter
Share on TwitterAbout the author

short for remote procedure call
Did you notice we build a product that helps you build message-driven systems? So yeah, maybe we're selling you something too, but at least we're honest about it. 😉
Note: This is not and should not be considered the only definition of microservices.
In NServiceBus, we default to
2 * LogicalProcessorCount, but this is fully configurable.