





On the importance of auditing
Any good accountant will tell you how important it is to keep receipts. I never imagined that advice was applicable outside of accounting and finance.
For example, I once worked on an ordering system, and one day, it was clear that something was broken. Orders that were expected to come from a well-known region on the globe weren’t coming in as usual. The incoming rate was exactly zero; definitely not the same rate as the week before.
🔗Something was misbehaving
The system was large and distributed, built using distributed architecture based on the tenets of service-oriented architecture (SOA) using messages and queues to connect different actors/endpoints. Call them “microservices” if you like, each of them physically deployed to datacenters in different regions all around the globe.
Finding the root cause of the issue turned out to be pretty easy. Our health monitoring system alerted us that message processing was throwing errors on a specific set of servers. Once the Operations team was able to retrieve log files, we immediately understood that something had gone awry with the latest deployment to that region.
The deployed version introduced a bug in the way region-specific regulatory rules were evaluated, causing order messages to fail. Orders! Orders with money!
Luckily, in our message processing system, so called poison messages were not discarded, but instead moved to an error queue for inspection. We had not lost any orders at all; the messages carrying them had just been quarantined for the moment, waiting for their chance to be processed again. The bug was fixed, a new version deployed, and orders started to fly once again.
Durable queues:
Durable queues guarantee that the messages will be persistent, meaning that once a message is received by the queuing system it is stored in a persistent storage, such as a hard disk or a database, before it is made available to consumers. This allows operating systems to be restarted or processes to crash without the risk of losing valuable information.
Dealing with persistent messages and durable queues means that the process consuming the message can crash during the handling phase without causing message loss, because it is persisted until the processing logic tells the queuing system that the message handling completed successfully.
🔗You can’t be lucky forever
We were very lucky to identify where the issue was. But it could have been a lot worse.
In the incident we faced, message processing was failing which caused messages to roll back in the queue, without message loss, causing a lot of headaches but no serious issues except processing delays. Instead, what if the business logic had a bug that caused messages to be processed successfully (technically speaking) but resulting in incorrect behavior? A successfully processed message would be deleted, and therefore lost.
Lost revenue, and unrecoverable scenarios in general, are a nightmare none of us would like to face. We realized that we needed to prevent these scenarios from happening in the future.
Distributed systems introduce monitoring issues that needs to be taken into account. Once the system is distributed and messages are traveling asynchronously, it can be very hard to have a bird’s-eye view of what is going on.
The easiest way to gain that holistic overview was to introduce another endpoint in the system whose role was to behave like an auditor that collects every single piece of information in the system and builds that bird’s-eye view.
Since messages are the entity that moves the system forward, the auditor needs to have a copy of each delivered message, the same way a tax auditor will hold on to receipts of purchases.
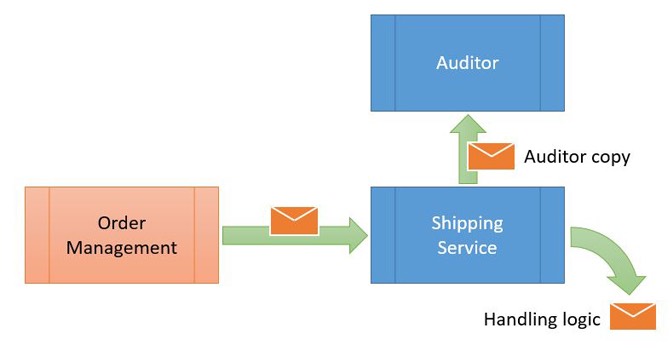
Achieving this goal was not that complex. In the next deployment cycles, we introduced an infrastructure feature at each endpoint that would intercept each incoming message and deliver a copy to the auditor queue. The auditor endpoint then stores the information in a database for further analysis.
From the auditor point of view it’s important to store all this information in a database, otherwise the messages will pile up and may run the auditor queue out of storage pretty fast. This is the leading reason why many system administrators disable this important and useful feature!
All a receiving endpoint has to do is forward copies of all messages it receives to the auditor queue. This frees each endpoint from the task of maintaining its own audit record. If every endpoint were required to store its own audit data, we would face two issues:
- Each endpoint would slow down, due to the new requirement of storing information to a centralized location.
- Every endpoint would become dependent on the centralized audit store, introducing an unwanted single point of failure.
Using this technique, we avoided creating a bottleneck at the endpoint level, which would occur if we had required it to complete additional auditing tasks in a synchronous fashion. Instead, we offloaded that work to the central auditor. The auditor endpoint, by using its own queue, is insulated from being bombarded by messages from many different endpoints at once; it is free to process audit messages at its own pace.
Designing and configuring the auditor as an actor of the distributed system, behaving like all the other actors and using the same communication approach, solves both issues.
🔗The missing piece
Having a copy of all the messages exchanged in the system is interesting and provides a lot of information, but is not sufficient to gain that bird’s-eye view we were looking for. Although each message had a Timestamp, allowing them to be sorted, we were not able to correlate them together, to see what messages were related to each other.
This was easily remedied by introducing ConversationID and a RelatedTo metadata on each message. These can be properties of the message itself, or better yet, headers of the underlying queuing technology.
Our ConversationID is generated by the infrastructure which guarantees that the ConversationID is copied to outgoing messages that are generated in the context of an incoming one.
The RelatedTo metadata contains the ID of the previous message in the flow; as for the ConversationID, the infrastructure guarantees that the RelatedTo metadata is automatically managed and guaranteed across multiple endpoints.
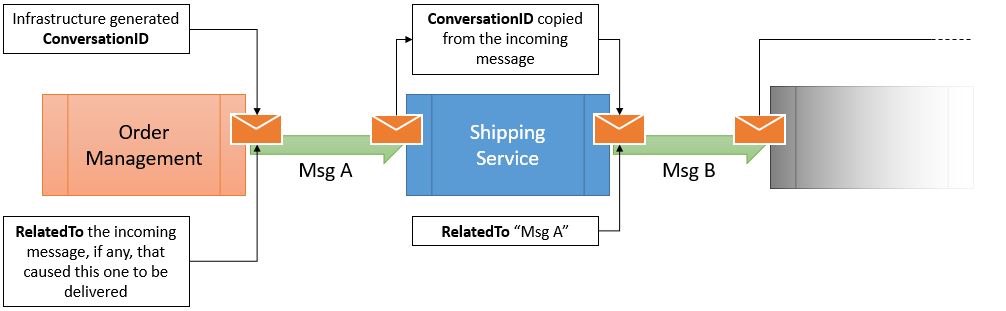
Having the ConversationID, the RelatedTo and the Timestamp metadata was the key to allow the auditing infrastructure to build the desired overview of the system.
🔗A picture is worth 1000 words
One of the difficulties with queuing systems is that you can’t look at the code and trace what’s happening from top to bottom. That’s because it’s loosely coupled, separate, and asynchronous. For this reason, having enough metadata so that you can later query what happened at run-time and see how things behaved will make your life much easier, not only in production, but during development as well.
Good messaging infrastructure that includes Timestamp, ConversationID and RelatedTo headers allows you identify related messages, and once identified they can be organized into a flow. These headers indicate cause and effect relationships between messages allowing us identify messages that were sent as a result of other messages and draw arrows between them.
Then you can construct a visualization of how an OrderAccepted event caused an OrderBilled event, which went on to OrderShipped. You can even build sequence diagrams to show how different nodes communicate with each other.
This auditing information is pure gold. You can visualize what happened in your production system and sort out where things went wrong.
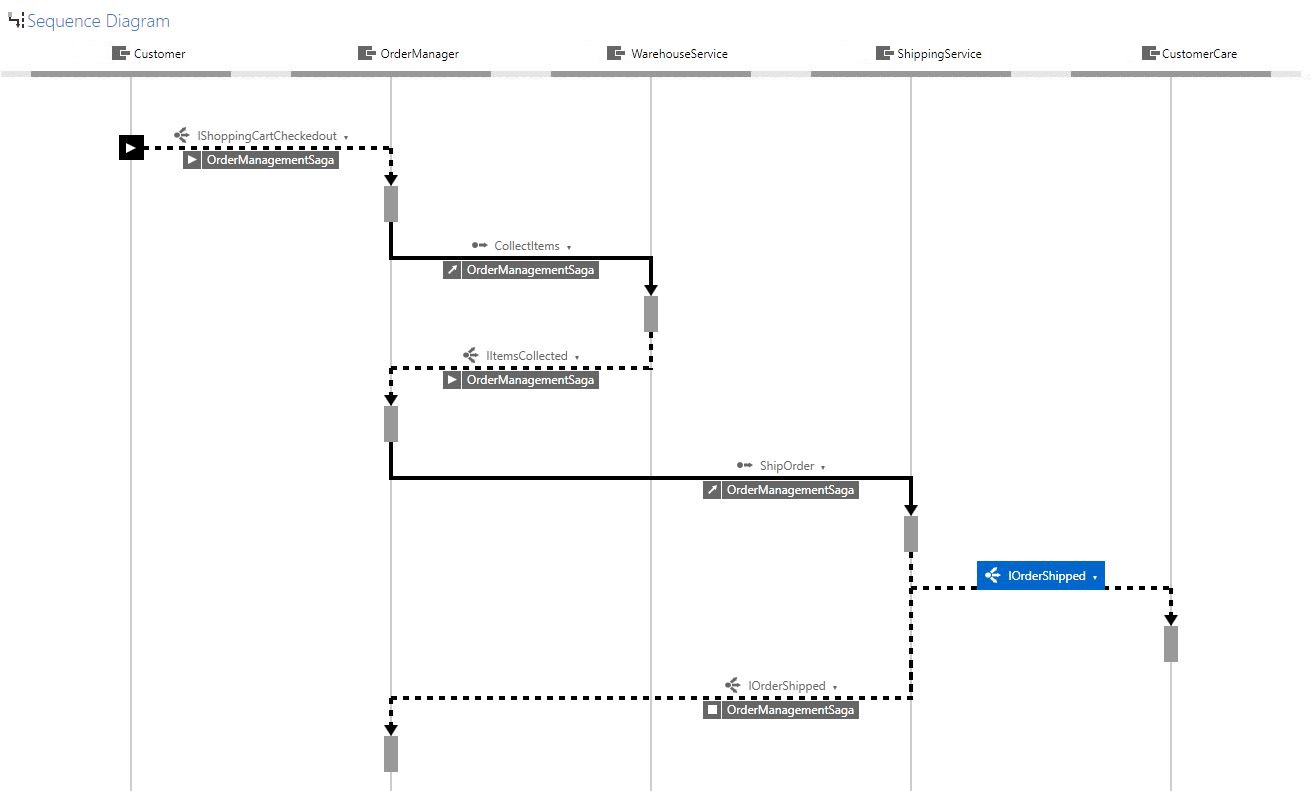
They say a picture is worth a thousand words. It’s also worth several hours of debugging.
🔗Summary
Your accountant will tell you to always keep your receipts. Without them, you can find yourself in a lot of trouble when the tax collector comes calling.
Distributed systems are no different.
When designing infrastructure monitoring for a distributed system, auditing is an easy way to keep receipts for activity within your system. Auditing allows us to track how the information flows and is changed while messages are traveling from one endpoint to another.
However, this information alone is not enough without a way to connect the dots, to see the correlations between messages, which can be accomplished by introducing a bit of additional metadata to each message that is audited.
At a bare minimum, you can reconstruct what was happening when things go wrong. With a little more effort, you can create visualizations to help you gain great insight into your system’s behavior at all times. It’s not enough to know what your system is doing. It’s also important to know why.
So next time, listen to your accountant.
About the author: Mauro Servienti is a solution architect at Particular Software, a Microsoft MVP for Visual C#, and is passionate about DDD, CQRS and Event Sourcing.
 Share on Twitter
Share on Twitter