





Status fields on entities – HARMFUL?
This article was originally published in NDC Magazine, no. 3 / 2014
It all started so innocently – just a little status field on an entity.
Now, there’s no way to know whether it was truly the root cause of all the
pain that came afterwards, but there does seem to be some suspicious
correlation with what came next.
Today, our batch jobs periodically poll the database looking for entities with status fields of various values and, when they do, the performance of the front-end takes a hit (though the caching did help with the queries). Once upon a time it used to be manageable, but with over 50 batch jobs now the system just can’t get its head back above water.
Even in the cases where we used regular asynchronous invocations, the solution wasn’t particularly solid – it was enough for a server to restart and any work not completed by those tasks would be rolled back, and any memory of the fact that we really need that task to be done gone along with it.
And don’t get me started on the maintainability or, more accurately, the lack of it. Every time someone on the team made changes to some front-end code, they invariably forgot at least one batch job that should have been changed as well. And since some of these jobs can run hours and days later, we didn’t really know that the system worked properly when we deployed it. And don’t bring up that automated testing thing again – we’ve got tests, but if the developer was going to forget to change the code of the batch job, don’t you think they’d forget to change its tests too?
If only I could say “never again”, but this is the third system rewrite that I’ve seen go bad in my career. And the alternative of continuing to battle an aging code base that gets ever more monolithic isn’t any more appealing.
It’s like we’re doomed.
🔗Did any of that sound familiar?
If so, you might be able to take some comfort in the fact that you’re not alone. Misery does love company, after all.
In any case, let’s rewind the story back a bit and look at some of the inflection points.
As time goes by, the logic of many systems gets more and more complex – starting slowly with some status fields which influence when logic should be triggered. Together with that complexity, the execution time of the logic grows often making it difficult for the system to keep up with the incoming load. It’s at that point in time that developers turn to asynchronous technologies to offload some of that processing.
🔗The problem with async / await
When you have some work that can take a long time, it is often appropriate to invoke it asynchronously so that the calling thread isn’t blocked. This is most significant in web frontend scenarios where the threads need to be available to service incoming HTTP requests.
Of course, as often is the case with web requests, we do want to give the user some feedback when the processing completes. This can be done by marshalling the response from the background thread to the original web thread – something that has been greatly simplified with the async/ await keywords in .net version 4.5.
The issue is, as mentioned above, that there is no built-in reliability around these in-memory threaded constructs. If an appdomain is recycled, a web server crashes, or any number of other glitches occur – not only is the work done on the async thread lost (if it didn’t complete), but the managing thread that knew what needed to happen next is also gone, in essence leaving our process in a kind of limbo.
Interestingly enough, sometimes batch jobs are created as a kind of clean-up mechanism to fix these kinds of problems. Also, since batch jobs frequently operate with database rows as their input as well as their output, it is believed that many of the reliability concerns of in-memory threading are resolved.
But we’ll get to that in a bit.
First, let’s talk about how the introduction of these batch jobs influences our core business logic.
🔗The impact of batch jobs on business logic
While developers and business stakeholders do understand that introducing these batch jobs into the solution will increase the overall time that it takes for a business process to complete, it is considered a necessary evil that must be endured so that the front-end can scale.
Unfortunately, what is often overlooked is the fact that the business logic that used to be highly cohesive has now been fragmented as shown in Figure 1.
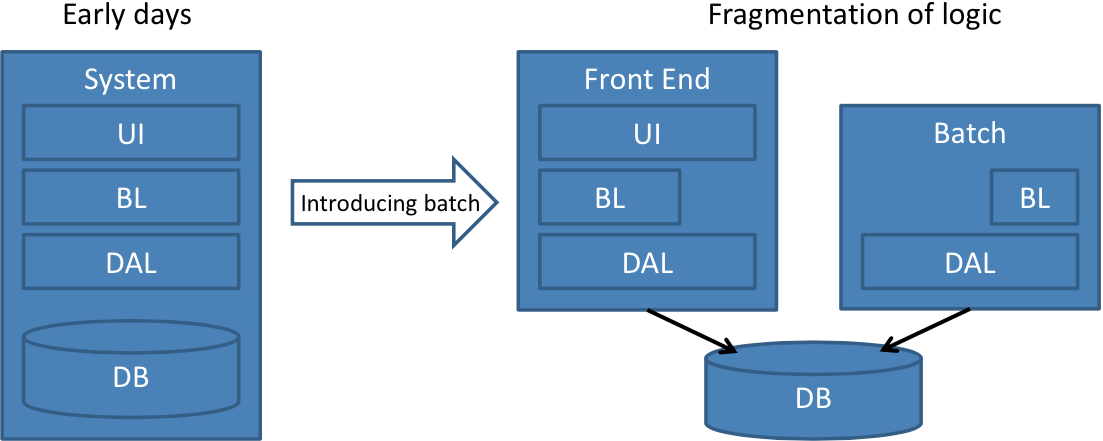
Now, if the logic was merely divided into two parts things might have remained manageable, but often the logic in the batch job is rewritten as stored procedures1 in the database or using other Extract-Transform-Load2 (ETL) tools like SQL Server Integration Services3 in an attempt to improve its performance. This is sometimes exacerbated by the fact that a different team, one focused on those other technologies, ends up maintaining that batch job.
And while a single batch job is likely not considered to be all that “evil”, it does seem that when a second batch job comes along they start to reproduce. And their devilish spawn is what ultimately brings our system to its knees with logic scattered all over the place.
And, although each decision taken seemed to make sense at the time, it seems that this road to hell was also paved with plenty of good intentions.
🔗The not-so-nightly batch
It was not so long ago that business was conducted from 9 to 5 in a specific time zone.
You could assume that your users wouldn’t need to access various systemsduring“offhours”.
But it’s a very different world these days – a more connected and more global world. Systems that used to be accessed only by employees of the company have been opened up for end-user access and these end users want to be able to do anything and everything on their own schedule, 24x7. In an attempt to keep pace with end-user demand, employees have similarly transitioned to an “always on” mode of work, on top of increasing travel demands.
In short, that once luxurious night in which we could run our batch jobs uninterrupted has shrunken so much over the past 20 years that it’s practically nonexistent anymore.
🔗The performance impact
The whole idea of moving logic into a nightly batch was so that it wouldn’t impact the performance of the system while the users were connected but it seems that this has boomeranged on us. Anybody who tries to use the system at a time when a batch is running gets significantly worse performance than if we had kept the original logic running in “real time” as at that time the batch is processing all records rather than just the ones that the user cares about.
On top of that, the fact that a batch job runs only periodically increases the end-to-end time of the business process by that period. Meaning that if you have a nightly batch, it could be that a given business process that started right as the nightly batch completed would have to wait almost 24 hours to complete.
If there are additional batch jobs that pick up where other jobs left off as a part of an even larger enterprise process, that sequence of batch jobs can cause these processes to drag on over a period of days or weeks.
And if we start looking at how failures are dealt with, the picture begins to look even more bleak.
🔗Dealing with failure
If any job actually fails as that can add even further delays. This failure could be caused by some other transaction processing the same record at the same time – a concurrency conflict. To
be absolutely clear, what this means is that the records which are the most active are the most likely to fail.
Unfortunately, there is no built-in way to have the processing retry automatically so developers usually don’t remember (or put in the effort) to create one. “It’ll just be picked up in the next cycle”, they tell themselves. However it may be just as likely that a conflict will happen on the next cycle as it did in the last one. Every time something fails, that’s another delay in the business process.
🔗Risks around performance optimizations
Sometimes developers attempt to optimize the performance of the batch jobs in an attempt to get them to keep pace with the ever increasing number of records in the system. One of the techniques that’s used is to operate on multiple records within the same transaction rather than doing one transaction per record.
While this does tend to improve performance, it has the unfortunate side effect of increasing the impact of transaction rollbacks when failures occur. Instead of just one record reverting to its previous state, all the records in that transaction get reverted.
This increases the business impact as more instances of the business process get delayed.
Also, as mentioned above, since the most active records are the ones most likely to fail, and the activity levels of various records fluctuate over time, it is quite possible that a given set of records will end up failing repeatedly as conflicts occur for different records within the same set.
In short, while more records can be theoretically processed per unit time when performing multi-record transactions, it may very well be the case that the rate of successful record processing actually decreases.
So, how do we resolve all of these issues?
🔗Use a queue and messaging (Part 1)
When developers hear the term “queue” they usually think of technologies like MSMQ, RabbitMQ, or something else that ends in the letter MQ (meaning message queue). While those are viable approaches, it is important to understand the architectural implications of a queue first.
A queue is a “first-in, first-out” (FIFO) data structure that enables different actors to interact in a decoupled manner.
The important thing about the “messages” that are pushed into and popped out of the queue is that they are immutable – meaning their values don’t change.
🔗How queues & messaging are different from databases
While it is common to have different actors reading and writing from tables in a database, the difference is that the entities in those tables are modified by those actors – meaning that they are not immutable. In this sense, traditional batch operations aren’t really using queuing or messaging patterns for their asynchronous communication.
While it is perfectly feasible to implement a queue on top of a regular table in a database, it is important that the code that reads and writes from that table treats its contents as immutable messages – not as a master data entity.
For this reason, it is usually desirable to abstract the underlying technological implementation of the queue from the application-level code – something like an IQueue interface with Push and Pop methods that have copy-semantics on the message objects flowing through the queue.
🔗Queue vs. database considerations
The advantage of using a databasebacked implementation of an abstract queue is that all data continues to flow through the exact same persistence mechanism resulting in simpler deployment, high availability, backup, and restore.
The disadvantage of using the database is that, depending on your database technology, it may be more expensive to scale the database to meet increasing performance needs than a message queue. That being said, just like there are numerous free and open-source message queues, there are also numerous free and open-source databases.
The main advantage of using message queuing technology is that it was designed specifically to address these kinds of problems. You’ll usually find that queues are able to achieve higher throughput as well as give you better control around how messages should be delivered and processed.
For example, you may have certain kinds of messages which represent data arriving from sensors at a high rate that don’t actually have to be persistent as you don’t care if they get dropped in case of a server crash. A message queue enables you to define these messages as non-durable and thus achieve much better performance. The main disadvantage to introducing message queueing technology is that it is another moving part in your system – something that administrators will need to learn how to configure, deploy, etc. That has its own cost (if the administrators aren’t already familiar with it).
🔗Leaky abstractions
While you might think that having this abstraction will practically insulate your system from the underlying technological implementation, it is important to understand that once the system is live there will be many messages flowing through it on an ongoing basis.
In order to switch from one implementation of a queue to another (to/from a queue to/from a database), it isn’t just a simple matter of changing the class that implements the interface. You may need to “drain” the system – meaning having it refuse any new requests until it finishes processing all the existing messages. This can mean significant downtime for a system.
Alternatively, you could write scripts which move all of the messages currently in-flight from one persistent store to the other. Like all data migrations, this can be tricky and should be tried and tested in pre-production environments sufficiently well before attempting it in production.
🔗Use a queue and messaging (Part 2)
If you start writing your application code using this kind of IQueue interface, adopting a more explicit message-passing communication pattern in your system, is that many of the problems mentioned above will be much easier to solve – let’s see why.
Once you use an explicit message object to pass data between actors (rather than having them polling entities of various statuses and updating those exact same entities), you reduce the contention on your master data entities. The message object communicates the important status changes and can serve as a more formal contract between those actors.
Just like any other interface in your system, a message contract should be versioned carefully, taking into account which consumers could be affected.
🔗Process state vs. master data
Entities with status fields often end up doing double-duty as both master data as well as holding the state of some longer-running business process. This probably isn’t the best idea, as stated by the tried-and-true Single Responsibility Principle4.
If you have an entity with a status field where that status changes values over time, that is usually an indication that you should create a separate processcentric entity that holds data related to the process that isn’t necessarily master data. While it can sometimes be tricky to draw the line between the two, it is a worthwhile exercise.
Don’t be influenced by the need to show the state of the process to the user – you can just as easily create a UI on top of a persistent process entity as you could on top of a regular business entity.
That being said, sometimes you can model these processes as a kind of event cascade as shown in Figure 2 and Figure 3.
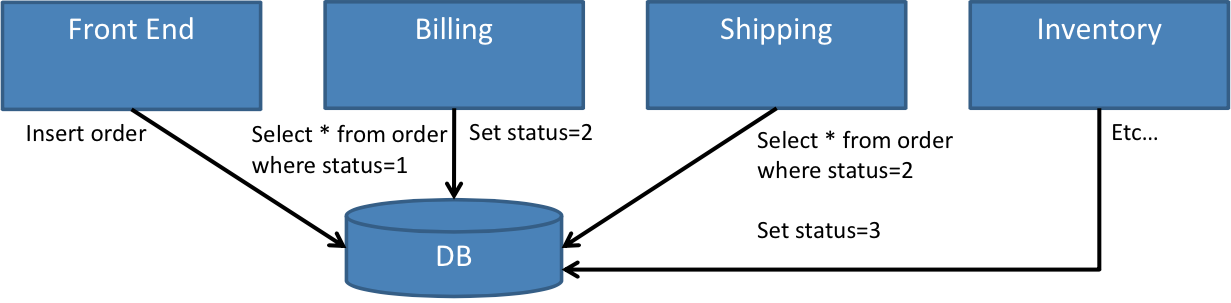

Often in a system, a combination of approaches is used with some eventdriven, publish/subscribe interaction and some process objects where we require more control and visibility of progress.
🔗The performance impact
Regardless of whether you use an actual message queuing technology or a database, once you make your messages immutable, you will have removed some of the contention on the entities (as they won’t be serving double duty as both a message and an entity anymore).
When taken together with building blocks with their own database schema, the rest of the contention is removed thus enabling us to perform the processing in “real time” rather than as a batch.
This combination can reduce business process times from days and weeks when performed as a series of batch jobs to minutes and seconds.
🔗Dealing with failure
The second significant benefit of message driven solutions is that many queues already have retry semantics built in so that even in the case of message processing failure, not only do things roll back but they get processed again automatically (and in the same real-time as before).
Queuing technology usually has additional capabilities in this area including the ability to move “problematic” messages off to the side (into a “poison letter queue”) so as to free up the processing of other messages. You can usually configure the policy around how many times a message needs to fail before it is flagged as a “poisonmessage”.
🔗Transitioning from batch to queues
The good news is that if you’re already making use of batch jobs, a lot of your code is already running asynchronously from previous steps – this makes introducing a queue much easier than if you had everything running in one big long process in your front end.
One challenge you may have, if a lot of the batch job logic was (re)written as stored procedures in the database, will be rewriting that logic back in your original programming language. You’ll usually get better testability along the way, but this can take some time.
It is [best to start your transition] from the last batch job in the sequence and slowly work your way forwards. That way, you’re not destabilizing critical parts in the business process where it isn’t clear what other jobs are depending on them.
When opportunities present themselves for building new functionality, or extending an existing business process, look to create new events that you can publish and have a new subscriber run the logic for those events using these new patterns. Hopefully, this will allow you to demonstrate the shorter time to market that this approach enables.
🔗In summary
Every time you see yourself creating a status field on a given entity, keep your eyes peeled for some batch job that will be created to poll based on that status. It would be better to create an explicit event that models what happened to the entity and have a subscriber listening for that specific case.
If your system is built using .NET and you’d like to use a framework that abstracts away the queuing system as well as enabling you to run on top of regular database tables for simpler deployment, take a look at NServiceBus. All of that functionality is available out of the box as well as giving you the ability to extend it for your own needs. Production monitoring and debugging tools are also available for NServiceBus as a part of the Particular Service Platform.
🔗References
1 Stored Procedure (Wikipedia)
2 Extract, transform, load (Wikipedia)
3 SQL Server Integration Services (Wikipedia)
4 Single responsibility principle (Wikipedia)
🔗Related topics
- Loosely Coupled Orchestration with Messaging (Udi Dahan)
- Death to the Batch Job (Andreas Ohlund)
- Event Driven Architecture - (EDA), SOA and DDD with Udi Dahan - DDD Denver Jan 2013
- Avoid a failed SOA: Business & Autonomous Components to the Rescue (Udi Dahan)
About the author: Udi Dahan is one of the world’s foremost experts on Service-Oriented Architecture and Domain- Driven Design and also the creator of NServiceBus, the most popular service bus for .NET.
 Share on Twitter
Share on Twitter