





Microservices: the future or empty hype?
As is common with the advent of new technology, there currently exists a lot of hype around the concept of microservices. Hype does not necessarily equate with superiority, and blindly following the hype can easily result in us making all of the same old mistakes in completely new and different ways.
In order to be more effective at software development, we need to take a step back and unravel the hype from reality.
There are a few broad classes of problems that microservices (in fact, any technology choice) cannot solve for you:
- Incorrect requirements – Clearly if we start with requirements that are wrong, it won’t matter how fast we can develop, deploy, or scale a system. This goes much deeper than you might think. How often do developers rush off to build exactly what the business stakeholders ask for, only to find out (much) later that it’s not what they actually need? Business stakeholders tend to present us with “solutions” masquerading as requirements. You don’t want the business stakeholders designing your system for you. That’s not their job.
- Weak processes – If you have almost non-existent unit testing, very little integration/acceptance testing, and ultimately the criteria for shipping software is “It works on my machine” then microservices certainly can’t save you.
- Bad habits – Clearly you, reading this technical article, do not have any bad coding habits, but we probably can’t say the same for every last member of our team. Microservices is not going to magically prevent them from writing crappy code.
And while the pain we feel on our projects may seem centered around deployment, the root cause may be more insidious, going back to bad requirements or poor habits. Microservices may help with deployment, but it is just as likely that they will uncover and potentially magnify bigger issues in our processes.
No tool or technology can save us from these problems. Rewriting all your code in Haskell or deploying NoSQL databases will not fix these issues. No other tool, technology, or architecture can fix this kind of stuff. This ultimately boils down to discipline and maturity around software development. It takes time to gradually level up all of the members of the team to work through all of the communication snafus within the team itself and between one development team and another.
There will be benefits from microservices, but the impact of those benefits will always be undermined by weak foundations.
🔗Back to basics
A foundational aspect of system design is the idea of a continuum between tight coupling and loose coupling, where in general we as a software industry have coalesced around this idea that tight coupling is bad; loose coupling is good. Tight coupling leads to huge, monolithic systems that are difficult to maintain or improve upon. Therefore, bad is monolithic and good is microservices. It’s important not to take this to an extreme where whatever we were doing before is bad, and the new thing is good, so we must apply that everywhere. Imperative programming is bad, functional programming is good. SQL bad, NoSQL good. And so on.
Let’s start with a single “monolithic process” implemented in a standard layered architecture. Instead of calling methods between layers, let’s apply a microservices architecture and divide each layer up into a separate process.
Have we changed anything?
Has the coupling improved in some way because now things are in a separate process?
Not really - in fact, probably the only thing we have changed is to add more latency, slowing down those method calls. From a logical perspective, the same data is being exchanged by the two sides. The coupling is the same.
A naive attempt to reduce this coupling would be to reduce shared data by storing it in a common database, and then passing only an ID between services. This is still coupling - it’s just been moved to the database. Now, if you want to change your database schema, it’s really hard to do because it’s not really your database schema anymore. It’s owned by both systems. It’s still logically coupled although that coupling is now much better hidden, and that’s not such a good thing.
It may seem like we’ve hit an impasse. If you keep components together in the same process, you still have the coupling. If you put them in separate processes, you still have the coupling. If you try to put the coupling in the database, it only makes it worse. It may feel like we’ve gotten to this point of there’s really nothing to do. There are no real guidelines as to which direction to go that’s going to solve these problems once and for all.
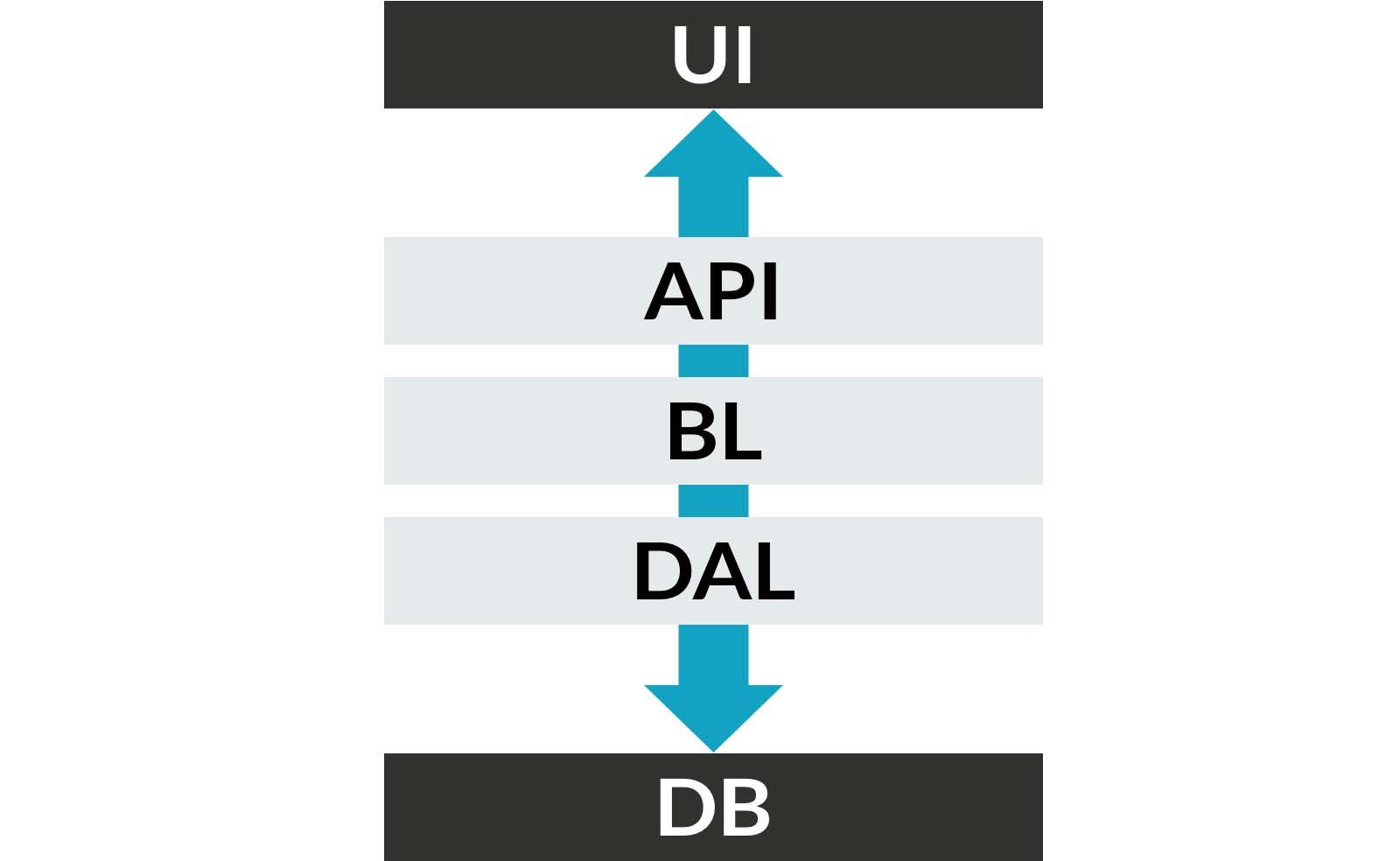
Looking at any typical system, you’ll probably see the classical layered architecture, as pictured. The inescapable reality is that you are going to have coupling between these layers. It’s a fact. Don’t fight it. Try adding a column to your database schema without touching every single layer. It can’t be done; the change must be accounted for in every layer of the diagram, from the database all the way up through the UI.
They tell us that adding layers decreases coupling, but we can easily see this is wrong. If something as simple as adding a column necessitates touching every single layer of the code base, then adding more layers is not going to help. It’s just more code that you need to touch.
It may be helpful to consider these layers “conceptually coupled” to each other. They are all coupled to the same concept. Embrace the coupling. Be one with it. Accept that it’s there for a reason. Once you reach this Zen-like state, you may remember another fundamental concept of object-oriented programming.
🔗Cohesion
The principles of object-oriented design call for building components that are loosely coupled but high in cohesion. Why do we spend so much time trying to reduce the former at the expense of the latter?
Sometimes we have components that, like the nucleus of an atom, really want to be together. It takes a massive amount of energy to split the atom, and once you do, you get a massive amount of destruction. We focus so much on loosely coupling everything from everything else that, in the end, we end up splitting the atom and making an awful mess.
If we take another look at our layered architecture, we might see that while there is tight coupling/high cohesion top to bottom, sometimes we can identify an element of loose coupling across vertical slices. The things that deal with one set of data don’t particularly care about other sets of data.
For example, if we’re talking about the retail domain, code that deals with products’ names and IDs and descriptions and images is really not that coupled to the pricing of a product and the discounting rules around it. It’s very superficial to only look at nouns when we model our data, saying that a product is a product is a product.
Don’t just assume that since the product is a “thing”, it should be loosely coupled from other “things”. Instead, look at it the other way around. Look at what things really want to be coupled to each other (usually these will be vertical slices spanning all layers) and then allow yourself to start to see boundaries that potentially slice apart your entities. Break these apart into loosely coupled, highly cohesive microservices, each potentially containing a regularly coupled classical layered architecture.
🔗Microviews
If we take this philosophy all the way up to the UI, this will lead us to a something quite different. Instead of keeping the entire user interface as its own complete layer (often built by a separate HTML5/JavaScript team), we split it up according to the same lines of coupling we mentioned earlier.
Imagine if a web page, instead of being one large software artifact, was a collection of widgets that happened to be laid out beside each other for a given URL. You would probably have a separate widget for a book’s title and its image, another for the customer rating, and yet others for price, inventory, etc.
The UI itself becomes componentized, where each “micro-view” talks to a “micro-backend” which uses some “micro-database” – all of which become part of a meaningful microservice.
This results in a kind of Lego block type model, so once you have a product price widget, you can now take that micro-view and compose that into many other pages. A shopping cart will use the product details widget, the customer rating widget, the price widget, and inventory widget. These Legos get arranged on page after page to compose full views.
Instead of redesigning a user interface for every single page that we need to do, we can take this collection of Lego blocks and put them together in slightly different ways to fill expanding new business needs.
🔗The long haul
It might seem that this would be really hard, at least at the outset. But be very careful making architectural choices about what’s the fastest implementation technique when you’re only examining one user story. In an engineering discipline, the important part to optimize is not how quickly we can build the first screen, it’s how quickly we can build the 100th screen, taking into account all the coupling we created while building the previous 99 screens.
What we want is a sustainable pace, meaning the ability to develop and deploy features at a rate that we will be able to maintain for many years.
The only time you should optimize for the early stage is if you are building a quick and dirty throwaway prototype. In that case you shouldn’t be doing any of this microservices stuff. But then you must have the maturity and discipline as an IT organization to actually throw it away.
🔗Scalability
A microservice approach, focused on long-term sustainability, does actually tend to scale quite well. One reason is because there isn’t just one monolithic database anymore (which is really hard to scale). Instead, by having each microservice with its own micro-database - queries can run in parallel over smaller sets of data resulting in much better performance as commands don’t end up locking out other transactions.
Also, the architecture of each microservice doesn’t need to be identical to others.
You may have one that is layered using a standard SQL database. Another may be more sharded in nature using a document database. Another may use a graph database to deal with a domain that is much more about the relationships between the various pieces of data as opposed to just big piles of data. Different microservices may even leverage different programming languages. The decoupling between microservices allows you to use the appropriate tool for each job, rather than trying to operate off of a single suboptimal standard enforced system-wide.
🔗Pushing boundaries
In order to really benefit from microservices, we must stop assuming that the boundary of a system is the most significant one. If we look across the enterprise, we see that there are a whole bunch of systems, and that a lot of the same kinds of data appear in those different systems in different ways.
A mobile app will likely show a lot of the same information that we have in our web front-end. It might be repeated again in a back-office system, and again in a separate portal site. This tells us that in our whole organization, there’s a certain amount of innate conceptual coupling between systems. If all our focus remains entirely on how to “microservice-size” a single system, we’re missing out on a lot of context.
What if a microservice was responsible for a given concept in all of our systems, not just one?
This sometimes gets people a little confused, because these systems are all written in different languages using different technologies. The idea of mixing technologies within the same microservice seems a little crazy, especially for an organization with separate teams for .NET, Objective-C, SQL Server, HTML5/JavaScript, etc.
If we want things to work out architecturally, that means we need to embrace cross-functional teams. More than just combining developers and testers on a team focusing on the same technology, we must take this a step further. We may need to have developers on the same team working in different technologies, where their code ends up being hosted in different systems and different processes, in order for us to maintain the cohesion and avoid things like duplication of data between microservices.
This is not necessarily a straightforward, prescriptive process. It requires a rethinking of so many things, challenging long-held assumptions across the entire organization.
🔗What does “micro” mean?
You may have heard that a microservice is roughly 100 lines of code. Clearly that doesn’t square with something being created by an entire team of developers using different technologies. (Maybe we should just call it a “service” instead.) A microservice is also clearly not a unit of deployment, or a process in their own right, because they span multiple systems.
These services need not even be deployed separately from each other. Consider a mobile app. We clearly can’t separately deploy a half dozen microservice processes on a mobile device and have them all talking to each other. Such a thing isn’t allowed.
In that case the mobile app, by definition a single physical process, hosts components from multiple microservices all together. Even in a more classic server-hosted software, this same principle applies. You can have a different physical deployment architecture than your logical architecture. Microservices do not need to be deployed separately just because they are logically separate.
A CPU-intensive component may require offloading work to a separate server. This is a separate process boundary, but that does not mean it must be a separate microservice. From a logical perspective, the coupling of the offloaded process does not change.
A microservice is not what everyone says it is. Stop worrying about the lines of code or the physical process boundaries and focus on getting the right amount of code with the right level of cohesion, with appropriate decoupling at a conceptual level. That’s a microservice.
🔗Stop building systems
Once we take a system and rip out all of these pieces that are ultimately the responsibility of the microservice, what’s really left of the system itself? What code is actually system code as opposed to microservice code?
Fundamentally, not very much. We’re left with a basic Lego board, and on that board, you affix these Lego blocks. The system itself is really just a shell in which to plug in your business capabilities from your microservices.
We need to stop “building systems” because a system is not what the business cares about. The business cares about the delivery of business functionality, which is not the same thing. Instead, we need to build business capabilities through highly cohesive microservices. Then we assemble individual systems by creating a mashup of cooperating microservices.
This also means we stop organizing teams around systems, but instead, around microservices. We can create cross-functional, cross-system teams, each working around a specific business capability. These business capabilities happen to be composed into multiple systems.
🔗Building cohesive teams
You might think that a single group of five or six developers would have to work on multiple microservices, constantly context-switching between them, in order to build a single system.
When you acknowledge that a microservice spans multiple systems, you can freely admit that there might be more work to do in System A than in System B or System C at a given point in time. But because our microservices span all of these systems, the team can more easily work around one business capability (building up domain knowledge along the way) and can remain cohesive in working together organically over longer periods of time rather than constantly context-switching between one microservice and another.
This tends to have great advantages on the people/processes side of things. It encourages developers to be able to be a little bit more flexible. Instead of being only an HTML5/JavaScript developer, that developer can do a little bit of this and a little bit of that as well.
It is likely that you may need technology experts in a consultative capacity to help all of the HTML5/JavaScript developers, and you will need an expert in database technology to be able to help all of the microservices teams in their specific data modeling.
There is room for this functional expertise, but it’s rare that you’re going to be seeing those kinds of people in a management role responsible for an entire microservice and nothing else.
🔗Closing thoughts
After we filter through all the hype, we can see that we have a lot to gain by applying a rational microservices architecture to our systems.
By abandoning our attempts to decouple the layers in our architecture, we can instead focus on creating conceptual service boundaries that span multiple software systems and multiple process boundaries. We can concentrate on achieving high cohesion vertically within our layers, and low coupling horizontally between data that is conceptually unrelated.
We can have cross-functional teams working on each microservice, delivering the same business capability across the enterprise, leveraging their inherent domain expertise in that business capability instead of reinventing the wheel within each system boundary.
We can stop “building systems,” with the narrow focus that implies, and instead compose them from reusable building blocks as requirements dictate.
It is a challenge to be sure, but with this architecture in place, we will be set up for long-term success, able to continuously build and deploy new business functionality at a sustainable pace for years and years to come.
After all, wasn’t that the goal all along?
About the author: David Boike is a senior consultant at ILM Professional Services in Minneapolis, Minnesota, a consulting firm specializing in building mission critical applications using the .NET Framework and related technologies.
 Share on Twitter
Share on Twitter